AI歌声合成?ボイチェン?Diff-SVCを徹底解説してみた!【やり方もあるよ】(2023-1-15訂正)
最近、Diff-SVCというのが海外でが流行り始めました。
AI音声合成だとも、AIボイチェンだとも、色んな言説が流布しておりますが一体「Diff-SVC」というのは何者でしょうか?
それでは早速ざっくり見てみましょう!
こんな風にDiff-SVCは「とある歌声」を「とある声質」へと高品質に変換できる技術です。
「Diff-SVC」とは?
Diff-SVCは中国のテンセントの研究部門にて開発された歌声変換AIです。
テンセントはEpic Gamesの筆頭株主で、同社が権利を持つ有名なゲームとしてはApex Legendsのモバイル版、League of Legends、PUBGのモバイル版、Pokémon UNITE、Re:ゼロから始める異世界生活 INFINITY等があります。
(恐らく「ゲームのローカライズにて声優の雰囲気を変えない」というのが開発動機かもしれません)
訂正:中国テンセントの発表論文は正確には「DiffSVC」で、Diff-SVCとDiffSVCとは全くの別物です。ちなみにこちらで紹介しているDiff-SVCは「diffsinger、diffsinger (openvpi保守版)、soft-vc」をベースに製作されたものです。
DiffSingerは中国の超名門校「浙江大学」で開発されたAI歌声合成用のニューラルボコーダーです。
Diffというのは「Diffusion」の略で、正式には「Diffusion model/拡散モデル」といいます。
これはStable Diffusion、NovelAI、Dall-E・2との画像生成AIでよく使用されています。
原理を軽く説明すると「とある画像にノイズを加えていくと、完全なノイズになる」、逆に「完全なノイズからノイズを除いていくととある画像になる」という感じです。

これを音声に適用すると「全ての音が満遍なく含まれたホワイトノイズからノイズを取り除くと、特定の音になる」という感じです

画像: Grad-TTS論文より
Diffusion Modelの合成品質はかなりは良いですが、「ノイズを取り除く演算を何度も行う」ことにより、リアルタイム性の求められる合成には向いていません。
(SynthVでは「Diffusion Probabilistic Models(DPM)モデル」としてDiffusionモデルを部分的に実装したようです。ノイズ除去演算をどうやって加速させたのかは謎です)
SVCは「Singing Voice Conversion/歌声変換」の略です。
Diff-SVCのやり方
こちらのjulieraptorの記事を参考にしました!ありがとうございます。
DIFF-SVC FOR VOCAL SYNTH USERS
①準備
音声データを最低1時間分(約300MB)、できれば3時間分(約900MB)分用意します。
これより少なくても良いですが、ある程度分量があると学習による品質向上速度が早くなります。
※1 音質さえ良ければ音程が外れてたり、噛んでたりしても問題ありません。
※2 歌声・話声・UTAU収録物、録り損じ等、何でもありです。
準備した音声データを15秒以下に切り分けます。
(いくら大きくても20秒以下が好ましいです。あまり大きすぎると学習に時間が掛かります)
AudacityのSilence Finder(無音検知)を使うと楽です
※Sound Finder(音検知)の方が変に切れることがないのでこちらを使ってください。使い方はほぼ同じです。
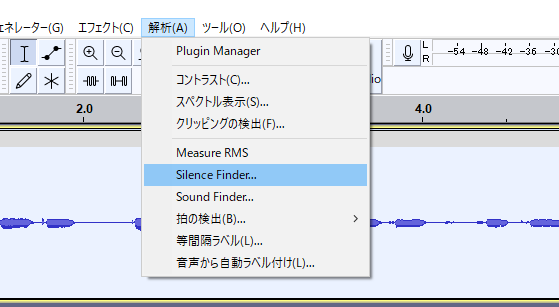
適当にパラメータを設定して適用すると、こういう感じの「S」ラベルができます。
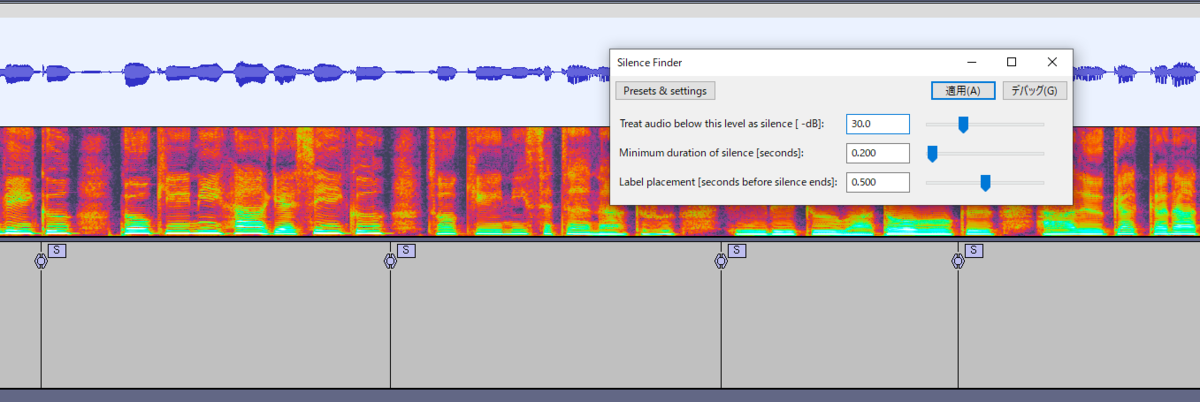
変な場所にSラベルが入っていないか調整して「複数ラベルの書き出し」から「ラベル」を選択して書き出します。
これで下準備は終了です。切り分けたwavをzipファイルにまとめて、自分のGoogle Driveにアップロードしておきましょう。
②モデルの学習
Linux環境での学習には挫折したので、Google Colabを使った学習方法について書きます。
まず、こちらのノートブックを開きます
Diff_SVC_training_notebook_(colab_ver_).ipynb | Google Colab
ここの「ドライブにコピー」をクリックして、ノートブックを自分のドライブに持って行きましょう。
ノートブックの設定からハードウェアアクセラレータが「GPU」になっている事を確認します。

もしProに加入してる場合はプレミアムGPU+ランライムの使用をハイメモリにすると学習が速く、そして中断されにくくなります。
確認したら、ノートをひとつずつ走らせていきましょう。
Preparation
・Check GPU type
→確認のために走らせてください
・Mount Google Drive
→グーグルドライブと繋ぐための作業です、絶対にやってください。
Step 1: Install Diff-SVC(インストール)

特にこだわりが無い限り「UtaUtau's Repo」を選択してください。
サンプルレートは基本的に24kHzを選んでください。(3時間以上のデータがある人はベースモデル無しの自分の声100%による学習ができるので、44.1kHzを選んでも大丈夫です。)
アップデートで44.1kHzのベースモデルが追加されました、基本的には44.1kHzで大丈夫です。
Step 2: Decompress dataset(データの解凍)
・singer_name
→自キャラの名前なり、自分の名前なりをローマ字で入力します。(多分日本語は避けた方が無難)
・dataset_location
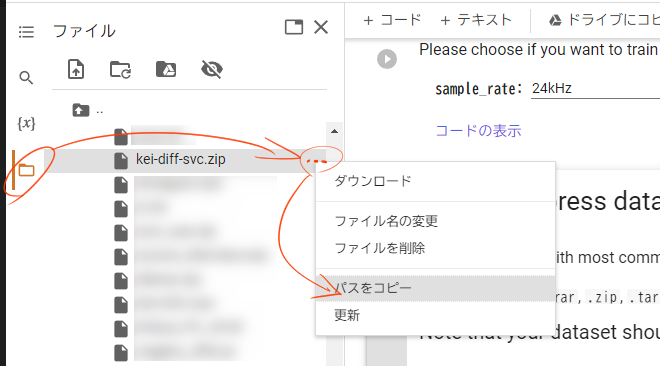
→先ほどアップロードしたwavファイルのzipのパスを入力してください。
ファイルのパスは左側ののフォルダアイコンをクリックして表示できる「ファイル」から簡単にコピーできます。(基本的には/content/drive/MyDrive/○○.zip)という感じになります。
※この動作は頻繁に使うので覚えてください
Step 2-A: Decompress training data(学習データの解凍)
今回は使いません、飛ばしてStep3に移ってください
Step 3: Edit training parameters(学習パラメータの編集)
・use_crepe
→チェックを入れる
・Set checkpoint interval
→学習何ステップ毎にモデルが生成されるかです。基本的に1000で問題ないです。Colab Proでコンピューティングユニットを買っている場合は多分5000くらいで良いです。
・Pretrain model usage
→ベースモデルありの学習に関するオプションです。
学習データが3時間以下の場合はチェックを入れると学習品質が向上します。
男声の場合はnehito、女声の場合はnyaruかopencpop、中性的な声の場合はlieeを選んでください。
※学習データが3時間以上かつ、Step 1で44.1kHzを選んだ人は使えません。
男声ならnehitoの44.1kHz、女声ならlieeの44.1kHzを選びましょう。
(lieeを使用する場合、「julieraptor」をクレジットしましょう)
・Use custom save directory
→完成したモデルをどこに置くかに関するオプションです。
Colabと接続が切れると進捗がゼロになってしまうので、基本的にはチェックを入れて「/content/drive/MyDrive/○○」など、自分のGDriveに設定しておくことをおすすめします
※ドライブの空き容量にご注意ください
・Resume training from a checkpoint
→今回は使いません
・Setup for small datasets
→音声データが少ない場合(多分30~40分以下くらい?)はチェックを入れてください
Step 4: Pre-processing
音声データを学習向けに変換します。かなり時間が掛かります。
Step 5-0 Tensorboard (run before step 5)
テンサーボード(学習の進捗状況)を表示します。上手く起動しないこともありますが大して問題はありません。
Colab Proじゃない場合はこのあたりでランタイムが切れます
Step 5: Training(学習)
学習を開始します。とりあえずランタイムが切れるまで待ちましょう。
Step 6: Package Model
Use custom save directoryオプションを使った場合は使いません。
③中断したところから再度学習
ランタイムから接続が切れた場合、途中から再度学習することができます。
事前準備
②と同じに設定してください
Step 1: Install Diff-SVC(インストール)
②と同じに設定してください
Step 2: Decompress dataset(データの解凍)
②と同じに設定してください
・dataset_location
②と同じに設定してください
Step 2-A: Decompress training data(学習データの解凍)
大幅時短できるので、ここ超大事です
・singer_name:
→Step2で設定した名前と同じ名前を入力してください
・preprocessed_data_location:
→特に問題が無ければ「/content/drive/MyDrive/diff-svc/data/○○」あたりに「シンガーの名前.7z」が入っていますので、それのパスを書きます
・config_location:
→上記と同じフォルダか、先ほど行った学習でのモデル保存場所に「config.yaml」が置いてあるのでこれを指定します。
Step 3: Edit training parameters(学習パラメータの編集)
・Resume training from a checkpoint
→前の学習で生成した最新のモデルのパスを入力してください。
それ以外は全て②と同じに設定してください。
Step 4: Pre-processing
Step 2-Aを実行したので飛ばしてください。
Step 5以降
②と同じで問題ないです。
④モデルを利用した歌声変換
さて、やっと楽しい時間がやってきました。
こちらのノートブックを開いて「ドライブにコピー」をクリックし、ノートブックを自分のドライブに持って行きましょう。
Diff_SVC_Inference.ipynb | Google Colab
Setup(セットアップ)
・Install Diff-SVC
Mode:
→初回起動の場合は「install」、もし使用中にDiff-SVC本体のアップデートが来たら「update」を選択してください
Repository:
→UtaUtaUtauを使用してください
Branch_name:
→どのバージョンのデータを利用するかです。今使ってるバージョンに致命的なバグがなければ空欄で大丈夫です。
・Mount your Gdrive
→GDirveに繋げましょう。
Load model(モデルの読み込み)
project_name:
→プロジェクトの名前です、なんでも良いです
model_path:
→先ほど生成したモデルのパスを入力してください
config_path:
→先ほど生成されたconfig.yamlファイルのパスを入力してください。
Upload your reference audio(音声のアップロード)
この機能を使って音声をアップロードすることもできますが、GDriveに直接アップロードした方が早いです
Input audio and adjust parameters
・wav_fn:
→wavファイルのパスです。GDriveに直接アップロードしたのに見つからない場合はファイルタブをパカパカするとそのうち更新されます。
・key:
→音声のキーを半音単位で変更します。しない場合でも「0」が入力されてないとエラーが出ます。大幅に変更すると滑舌等が崩壊する可能性があるので気を付けてください。
・pndm_speedup:
→値を大きくすると早く合成出来ますが、50以上にすると音質が低下するので弄らない方が良いです
・wav_gen:
→合成されたwavをどこに保存するかです。
デフォルトはランタイム内になっているので、「test_output.wav」の前に「/content/drive/MyDrive/」を付けてGDrive内に保存するよう変更するといいかもしれません。
・add_noise_step:
→use_gt_melパラメータを使用するときに使用できます。1にすると学習音声100%、、1000にすると完全にモデルの音声に寄ります。値が300付近になると、音色が混じっている感じになります。(このパラメータを非常に低く設定して、pndm_speedup値を減少させるとレンダリング品質が高くなるらしいです)
・thre:
→元音源が綺麗なら値を増やせます。音質が微妙なら値を減らしてください。
※use_crepeにチェックを入れなかった場合は使えません。
・use_crepe:
→チェックを入れるとピッチの計算方法にcrepeを使用します。
基本的にはチェックを入れると良い感じになります。オフにした場合、公式Diff-SVCレポジトリを使用した場合はparselmouth、UtaUtaUtauではHarvestが利用されます。
ただ、個人的にはUtaUtaUtauのHarvestを使った方が品質出ます。
・use_pe:
→チェックを入れるとメルケプストラムからピッチを入力し、オフにすると生音声のF0が使用されます。基本的にはチェックを入れると良い感じになります。
・use_gt_mel:
→チェックを入れると良い感じになりますが、元音声らしさは若干失われます。(説明によると、AIによる画像生成のimage-to-imageと似ていて、入力音声とターゲット音声の混合音声になるとのことです)
※キー変更機能は使えません
(雰囲気としてはこんな感じ)

・Display results&Display graph
→それぞれ「出力した音声を再生ボタン付きで表示」「変換元と変換後の音声をグラフで表示」してくれます。
前者は保存パスを指定している場合はあまりが意味が無く、後者は趣味の範疇なのでお好みでどうぞ。
⑤学習におけるアドバイス
◆データについて
・UTAU音源だけでも学習できますが、ある程度歌のデータもある方が良い感じのデータになる感触がしてます。
・どんな音声でも良いです。日本語でも英語でも韓国語でも、意味のある言葉でも、意味の無い呪文でも、もはや言語としての形態を為していなくても、歌でも、ラップでも、喋り越えでも、音痴でも、噛み噛みでも。
というのも、この学習では「声質」のみを学習するので、モデルの良し悪しは「元音声の音質」にのみ左右されます。
・「こんな音、学習して良いんだろうか……?」みたいな事を考えず、めっちゃ高い音やめっちゃ低い音を入れるとモデルの対応音域が広くなります。裏返ってても問題ないです。
・アペンド(表情)音源等を入れると恐らく表現豊かにはなりますが、データ内で声質が分散してるので良い感じの音源になるにはかなりのステップが必要だと思われます。
・多分10万stepくらい回せば大体の場合では良い感じになると思います。20万stepを超えたあたりからは趣味の世界になります。
・ノイズはある程度除いてから学習させると良い感じになります
◆Colabについて
・早く完成させたいならコンピューティングユニットを買ってプレミアムGPUで3時間くらい回すと10万ステップくらい進みます。
⑥注意点
・機械学習を不可としている音声合成ソフトが多数ありますので気を付けましょう。
A.I.VOICE, CeVIO AI, Coefont CLOUD, COEIROINK, VOICEPEAK, SHAREVOX,VOICEVOXの一部キャラ
・また、有名人や版権キャラクター等のDiff-SVCモデル製作は黒に近いグレーゾーンです。
(このあたりが参考になります)
⑦デモンストレーション
・1時間の歌・喋り等で学習した音声&ステップの比較
・4時間分のUTAU音源で学習した音声&ステップの比較
・デモソング(日本語)
・デモソング(英語)
⑧感想
技術としては物凄く面白いんですが「これって音声・歌声合成っていえるの?」という部分があってちょっともにょる部分があるような……ないような……。