【図解】波形とスペクトログラムで見るラベリング/原音設定の極意
ふと、UTAUの原音設定やNNSVS/ENUNU用の音素ラベリング向けのお手軽な資料があまりなかったり、インターネッツの風化でいくつかが消えてたことに気付いたので書いてみることにしました。
「極意」とはありますが、あくまで「こういうのが一般的な正解」というのに自己解釈を加えています。
最後には自分の耳を信じてください。
合ってるか分からないなら、何度もその区間を再生してください。
- ⓪前提
- ①母音・ン
- ②無声摩擦子音(サ行)
- ③無声破裂子音(カ・タ・パ行)
- ④有声摩擦子音(ザ・ヴァ行)
- ⑤有声破裂子音(ガ・ダ・バ行)
- ⑥ハ・ファ行
- ⑦マ・ナ行
- ⑧ラ行
- ⑨半母音(ワ・ヤ行)
- ⑩拗音を含む音(キャ・ギャ・ビャなど)
- ⑪小さい「っ」(cl)
- ⑫無声化(大文字のA,I,U,E,O)
- ⑬出だし
- ⑭NNSVS/Sinsyの仕様上の注意
⓪前提
おすすめツール
・VLabeler
UtaFormatixを作ったコリン氏が制作したラベリングソフト
NNSVS, Sinsy, UTAU, 何でも扱えます。
歌詞付きのUSTを読み込んで、その歌詞をどういう風に変換するかを指定できたり、Audacityのミリ秒ラベルをNNSVS式のナノ秒に変換してくれる機能もあります。
・おすすめ設定
スペトログラムの設定で配色を無色以外に変えます。
個人的にはSunsetがおすすめです
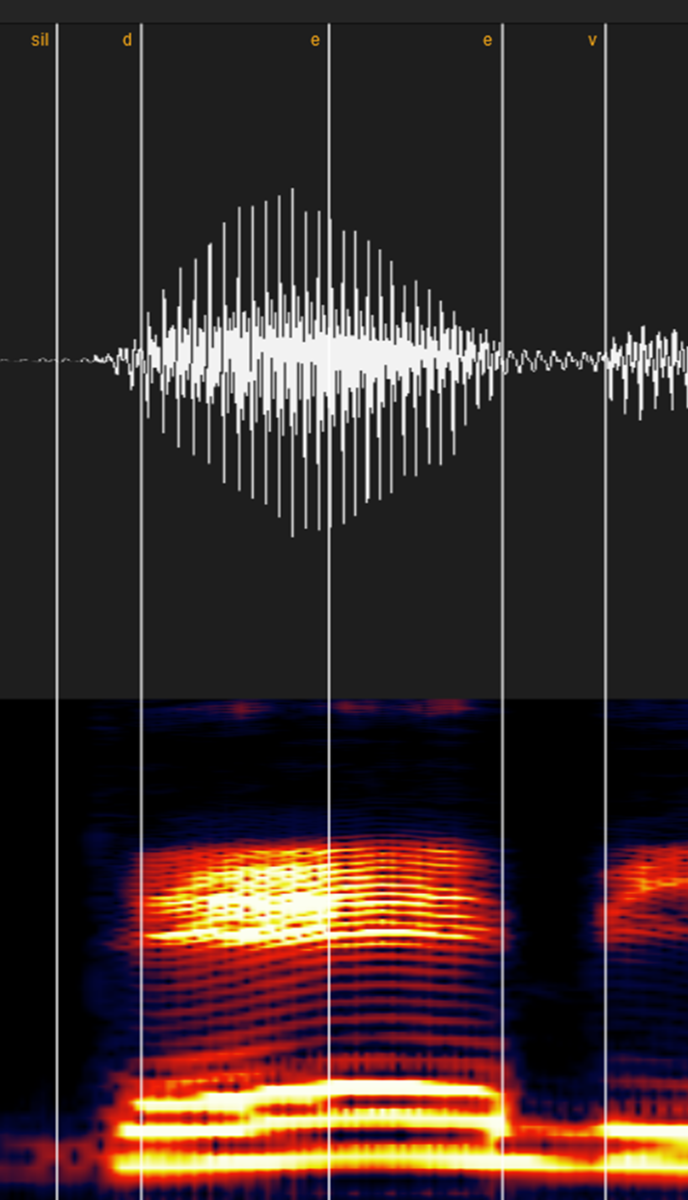
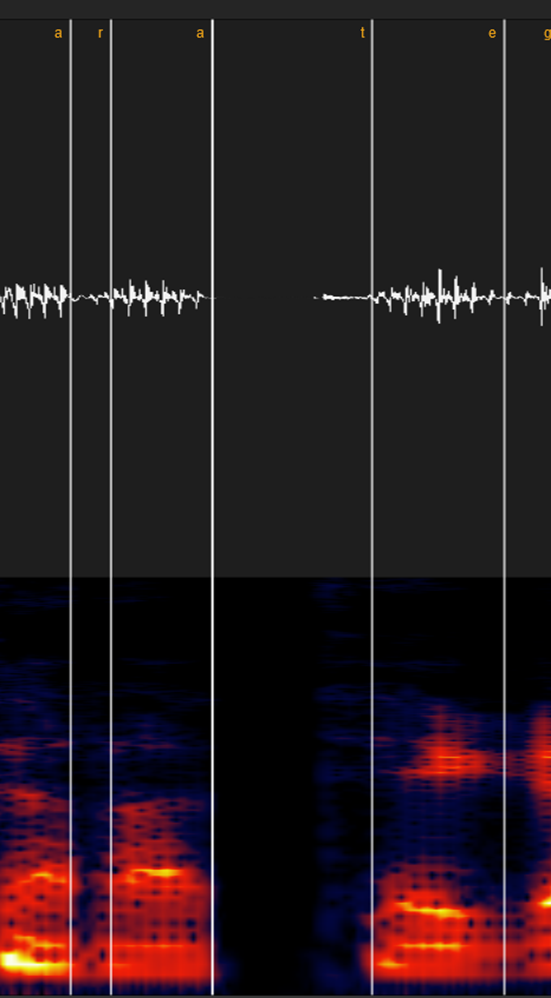
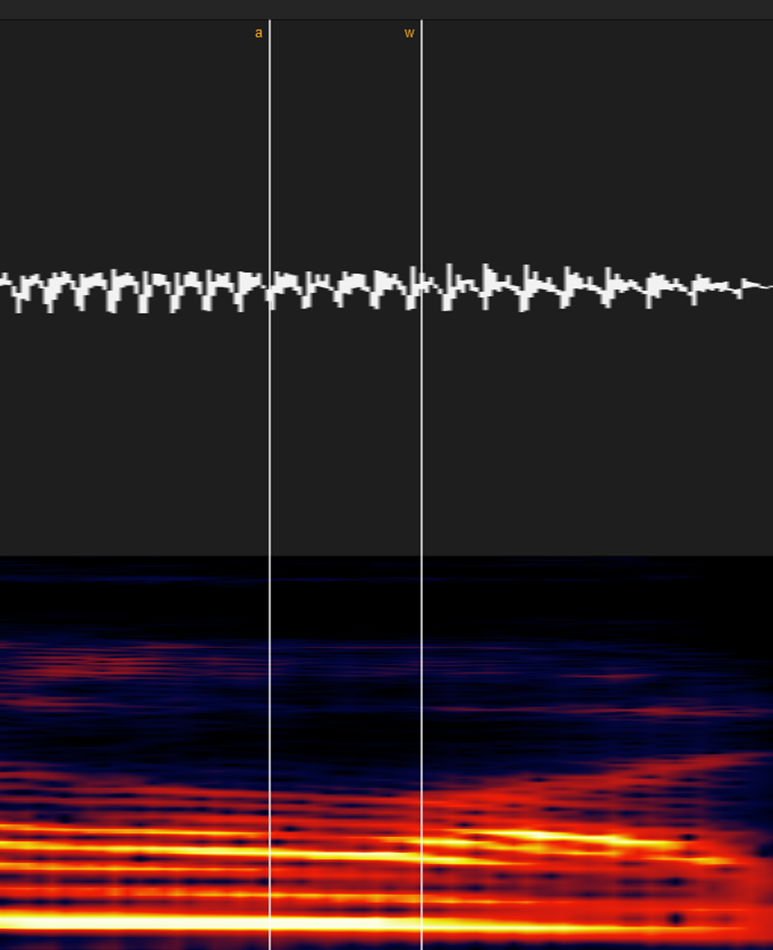
①母音・ン
・同じ母音の場合(例:あ-あ)
UTAUなら基本的にはどこでも大丈夫ですが、歌声系統なら「音程が変わる」「一瞬音程が下にブレる」「スペトログラムの明るさが地味に違う」などで若干色が変わる部分がある場合はそこを境に気持ち区切りましょう。
※エッジボイスが入ったり、空白がある場合は小さい「っ(cl)」として処理してください(後述)
それでも分からない場合は、楽譜の音符の長さを考慮して等分しましょう。
・違う母音の場合(例:あ-い)
母音が切り替わる場所で区切ってください。
分かりづらい場合は波形やスペクトログラムを拡大してみて「切り替わりっぽい中間点」に置けば大体大丈夫です。
(前述の「音程が変わる」「一瞬音程が下にブレる」「スペトログラムの明るさが地味に違う」等も判別に有効です)
※エッジボイスが入ったり、空白がある場合は小さい「っ(cl)」として処理してください(後述)
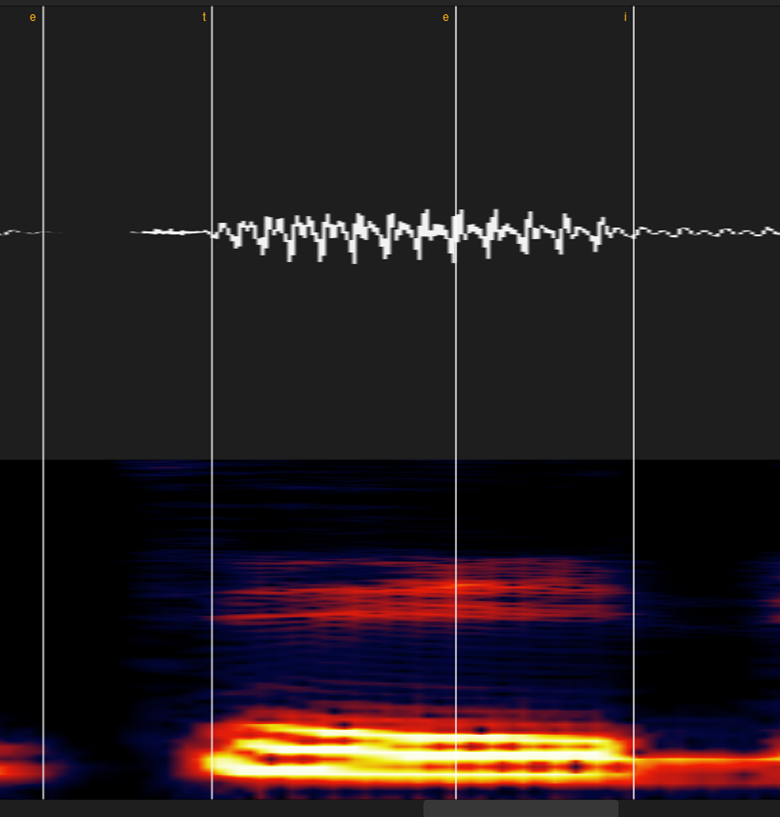
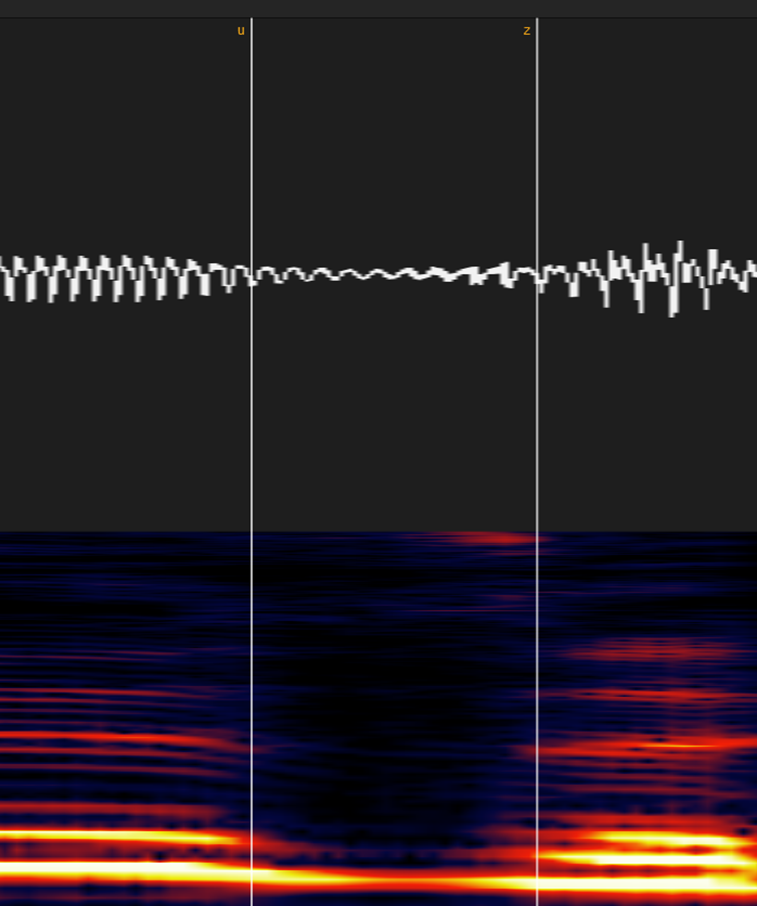
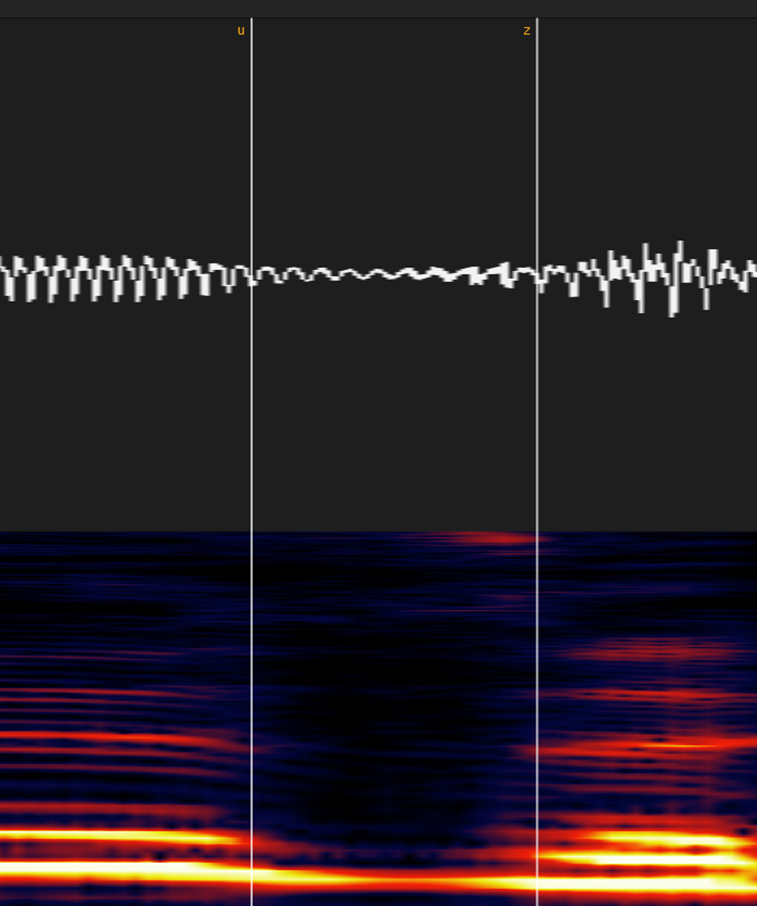
②無声摩擦子音(サ行)
スペクトログラムの線が音声がないところ+波形でチェックします。
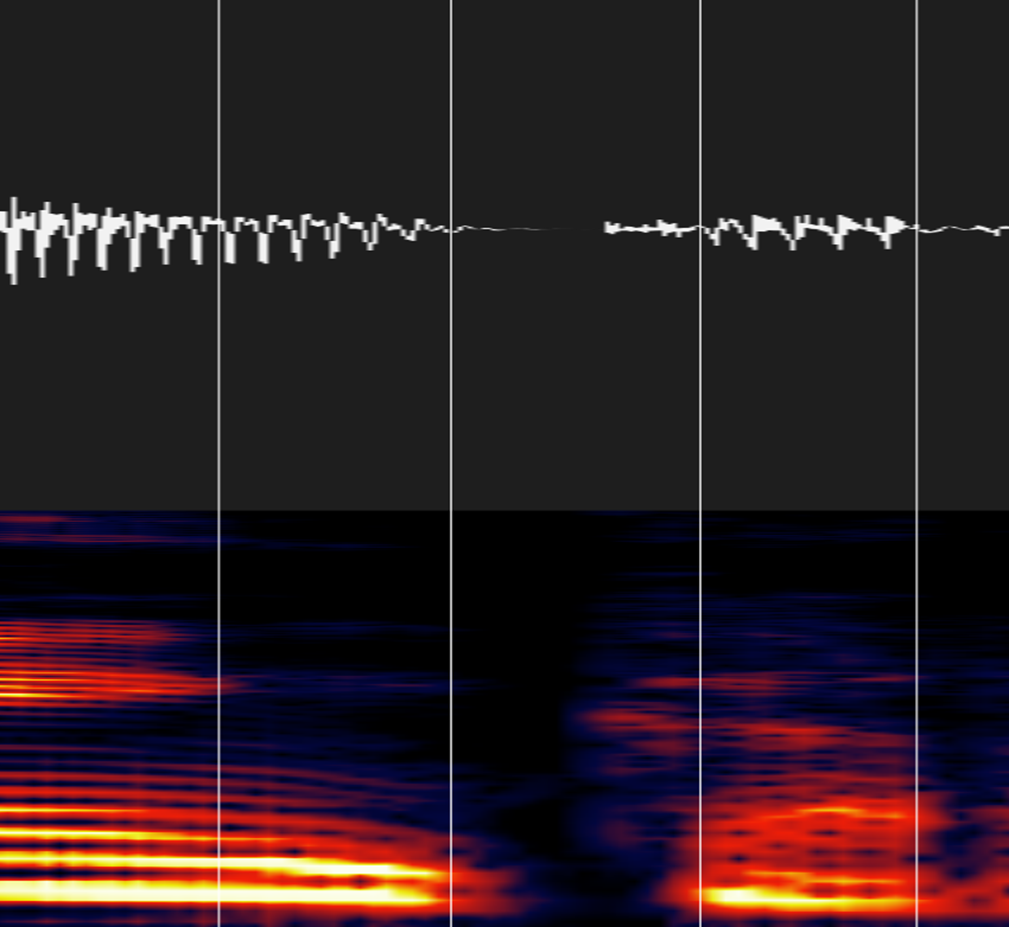
③無声破裂子音(カ・タ・パ行)
破裂音のパルス部分+無音区間を子音として区切ります
④有声摩擦子音(ザ・ヴァ行)
サ行と似てますが子音にも音程があるので、波形やスペクトログラムの減衰を見て設定してください。

⑤有声破裂子音(ガ・ダ・バ行)
場合によっては「カ・パ」行と同じですが、場合によっては「ザ・ヴァ行」のようなスペトログラムの線がある子音+破裂音のパルスが組み合わさっている場合があります。
⑥ハ・ファ行
サ行とほぼ同じですが、息の漏れる音は「母音が地味に混ざる」という性質上どこまでが子音か判別がつきづらい場合があります。
「音量が急激に変わり始める場所」→「スペクトログラムの線が急に濃くなり始める場所」という風に覚えてください。
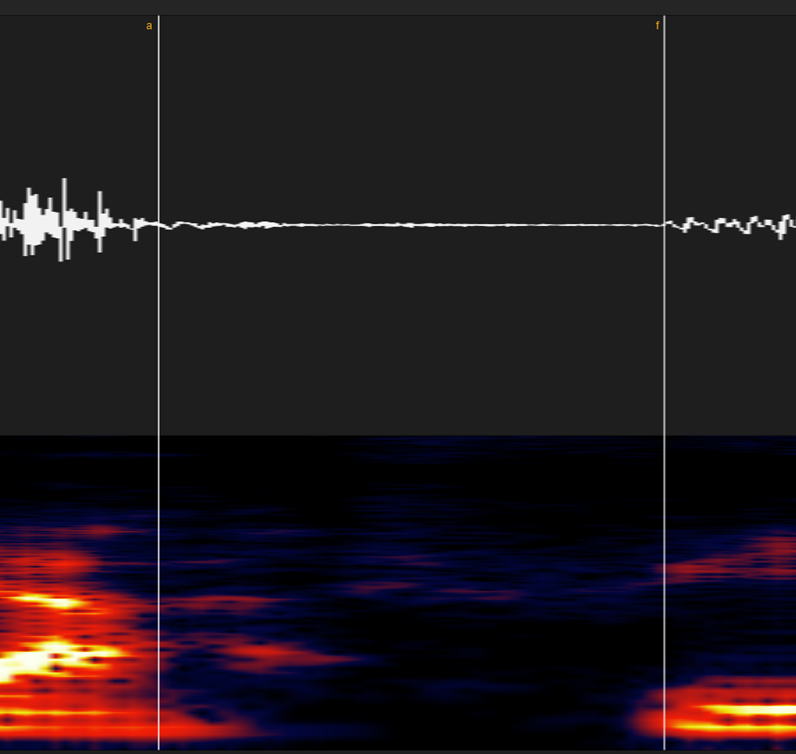
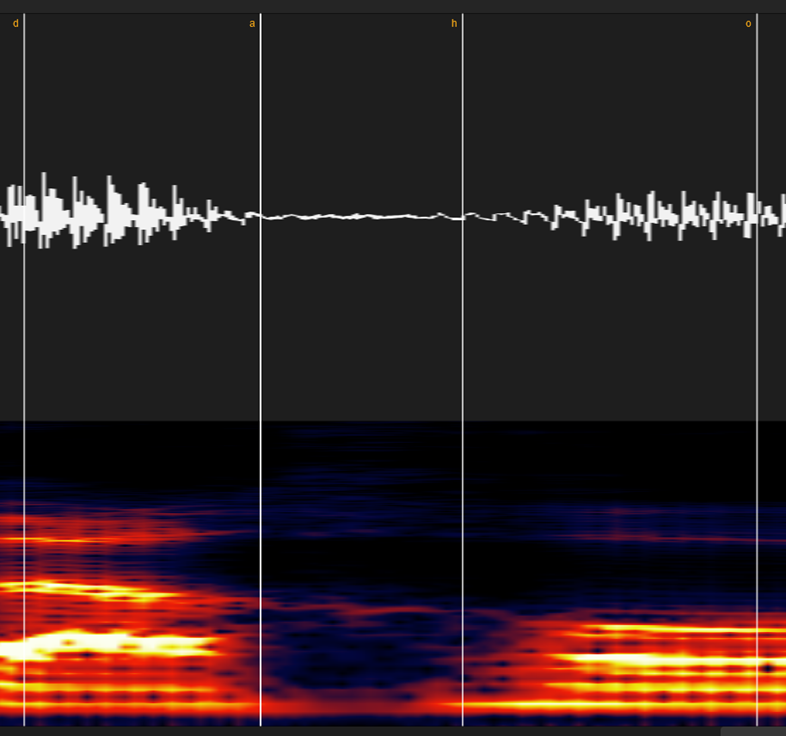
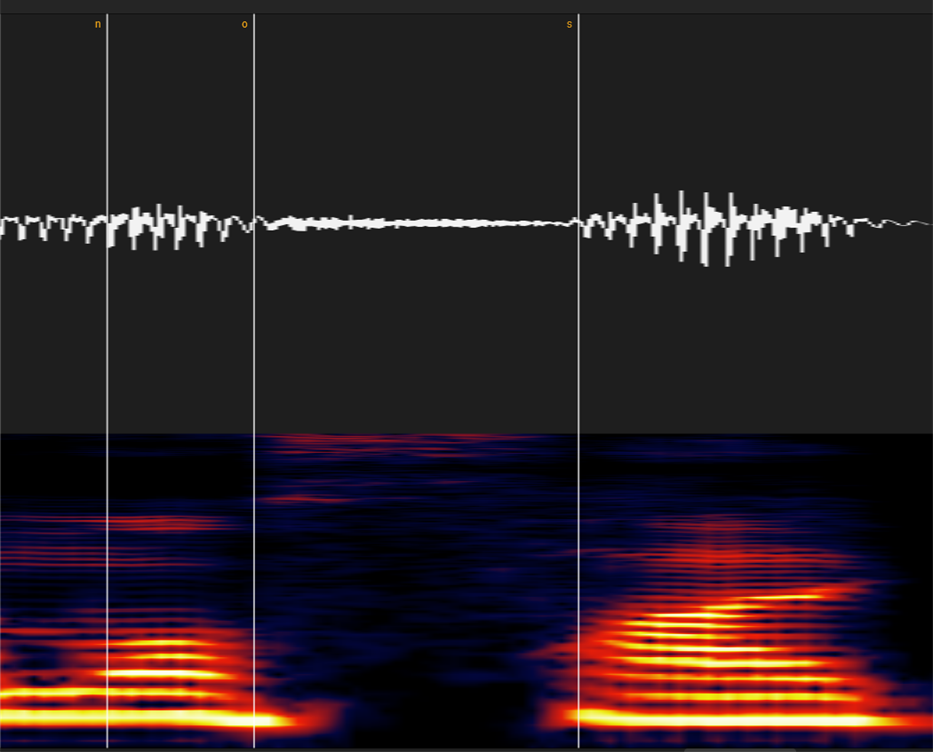
⑦マ・ナ行
波形で見てもかなり分かりやすい部類の子音ですが、スペトログラムだとさらに分かりやすいです。
「ん」(N)から続くと、どこからどこまでが「N」OR「m/n」か分からなく場合もありますが、その場合は割と適当で大丈夫です。
(強いて言うなら「m/nよりもNの方が長い」「なんとなく色のや波形の雰囲気が変わ)った場所」位の感覚で大丈夫です。
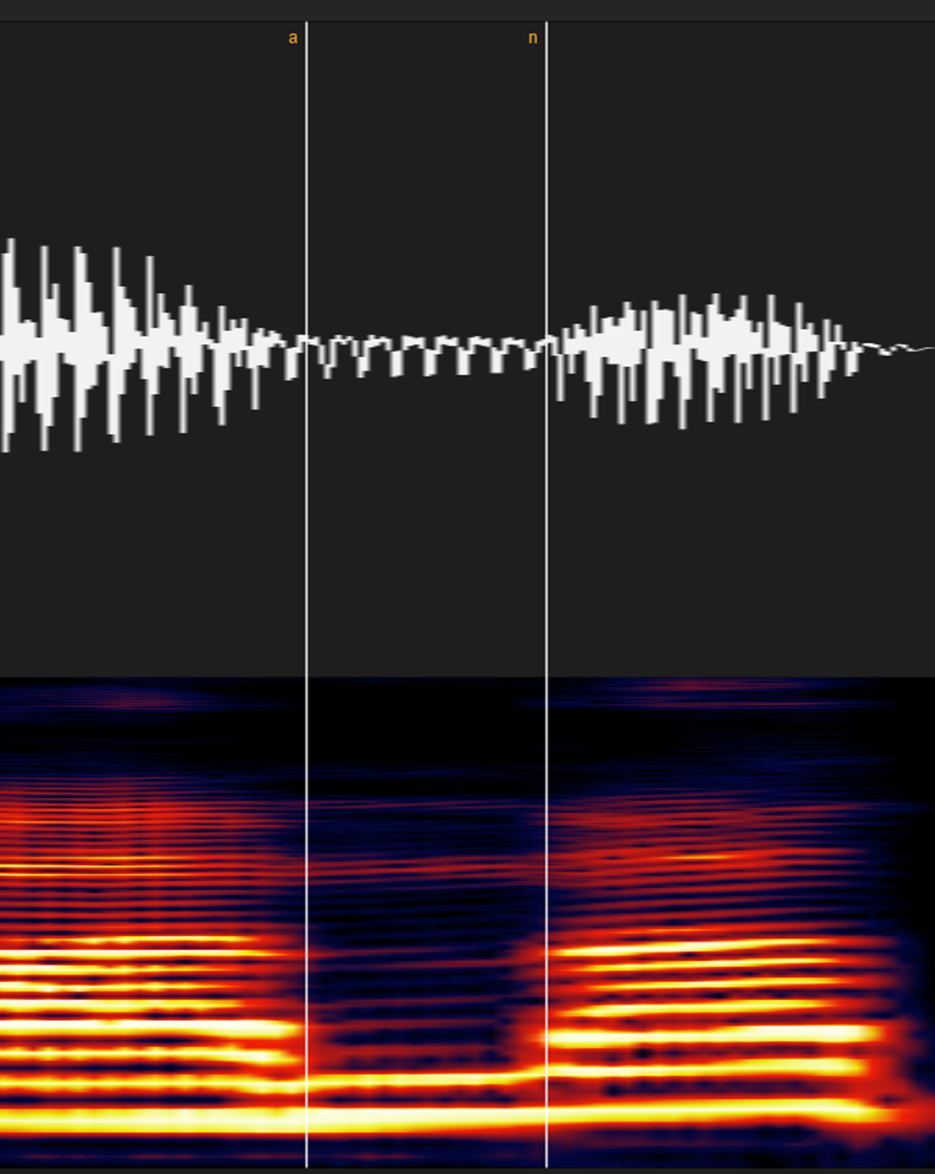
⑧ラ行
短い場合は「ガ・バ」行とほぼ同じです。スペトログラムが一瞬減衰して完全に元の色へ戻るまでの区間があるので、そこをラベルしましょう。
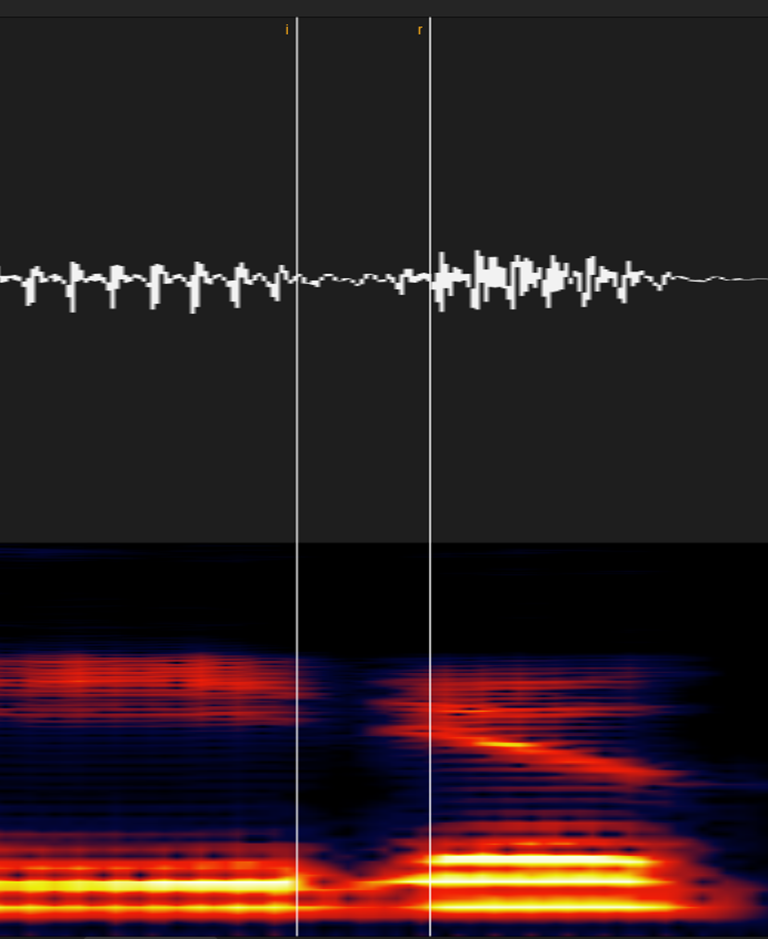
ラ行の子音が長い場合は「英語のL」に近くなりますが、これは「マ・ナ行」と同じ部類です。
⑨半母音(ワ・ヤ行)
これは時と場合によってかなり難しくなります。
基本的には耳が頼りですが、あえて言うなら「スペトログラムに分かりやすい光の偏りに変化が起こる前の区間(一帯)」という感じです。
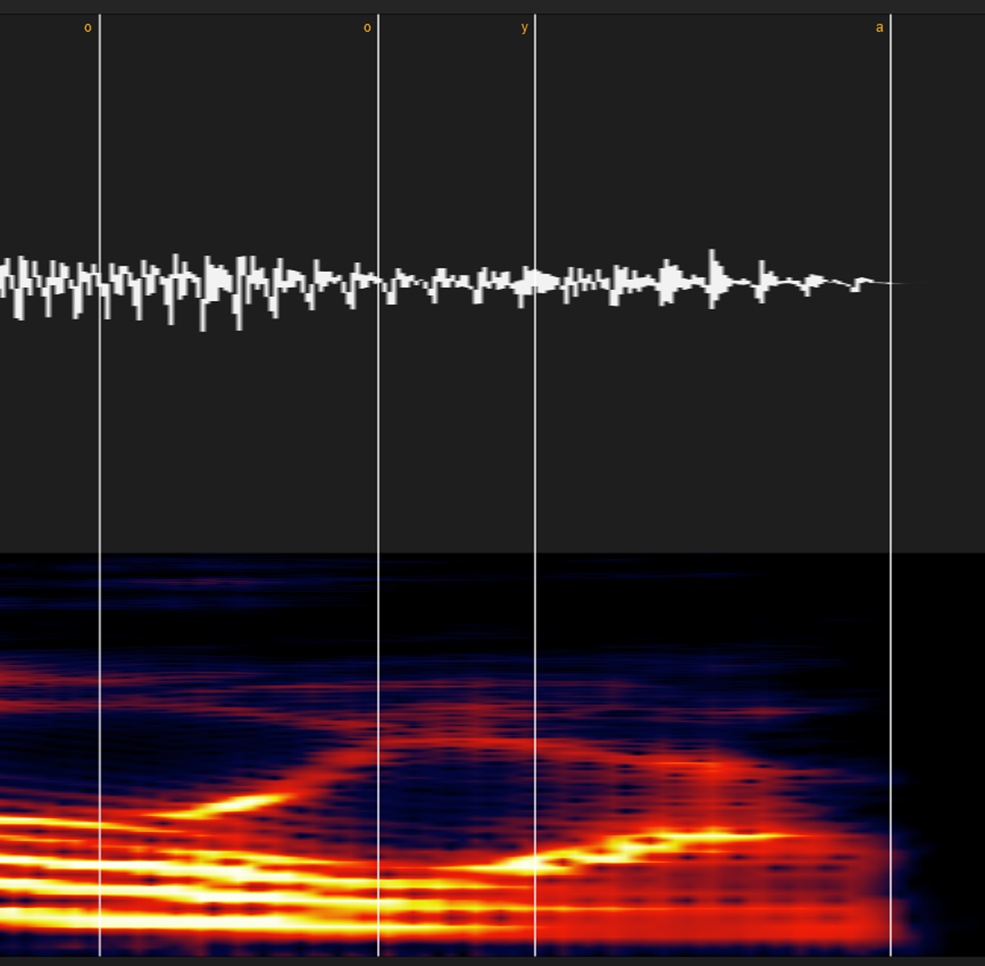
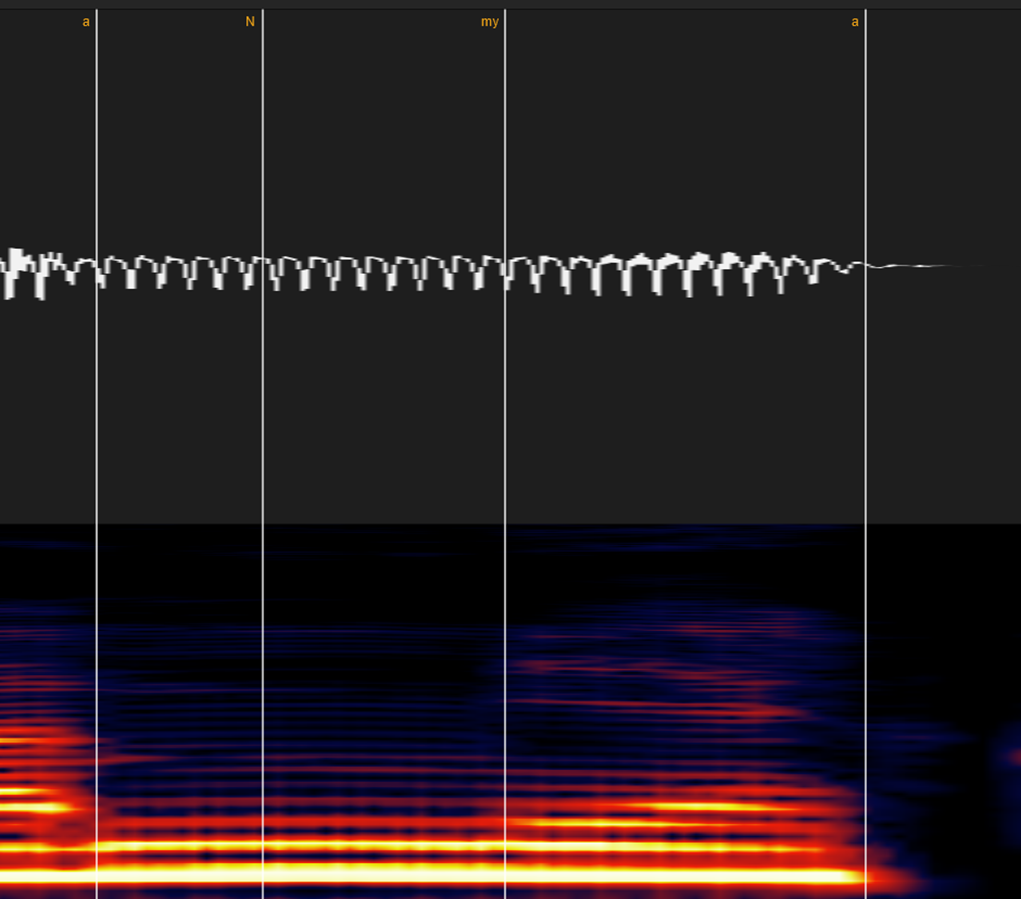
⑩拗音を含む音(キャ・ギャ・ビャなど)
myならマ行式に、kyならカ行式に、「◯y」のyを無視してラベルしてください。
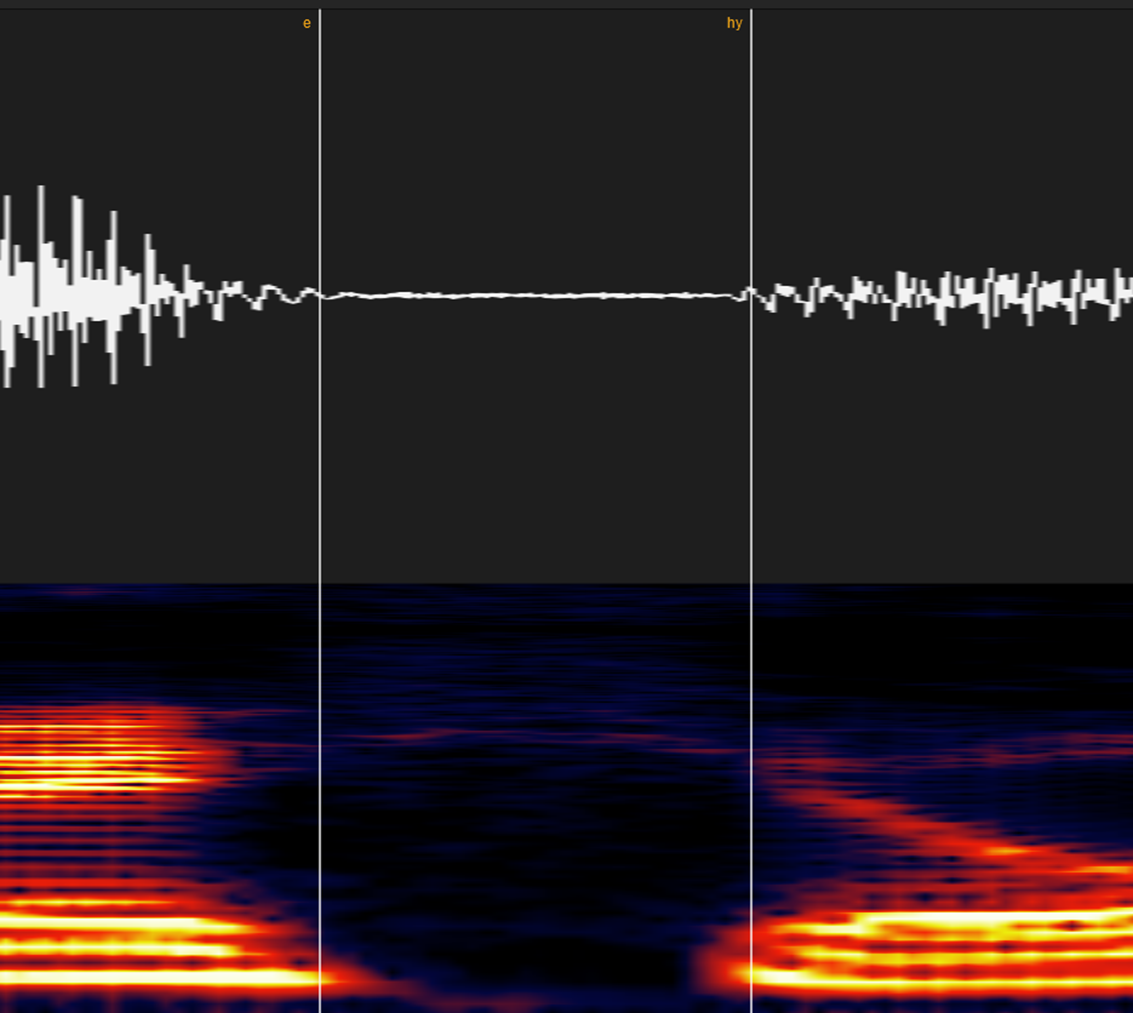
※以下理論的な説明
例えば「あみゃ」は[a my a]という表記/発音になります。
ここに小さい「っ(cl)」を入れると「あっみゃ」[a cl my a]となります。
[a cl my a]を発音通りにひらがな表記すると「あんみゃ」になります。
ここでもし「my」の子音区間に「y」を含めてしまうと、小さい「っ(cl)」によってその後の子音区間が均等に引き延ばされるので「a 【NNNmmmyyyy】 a」となり、発音は「あ【んんんみいいい】あ」となってしまいます。
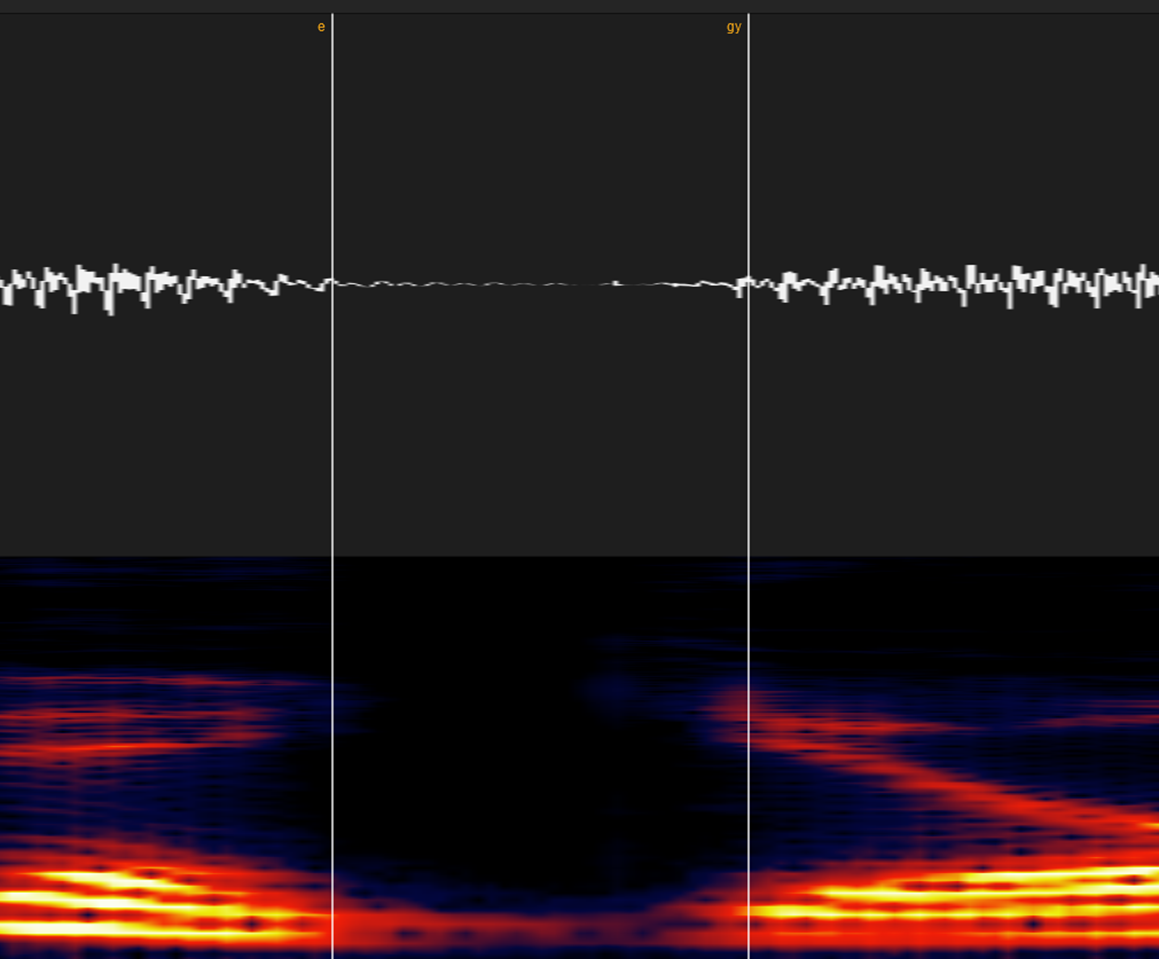
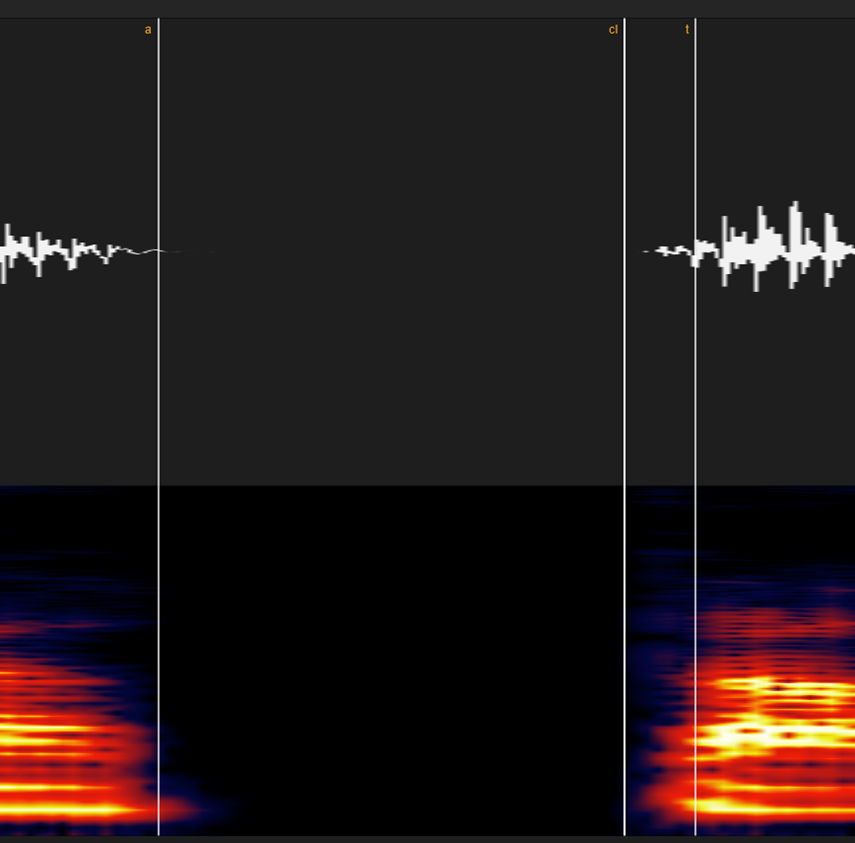
⑪小さい「っ」(cl)
これに関しては様々な宗派が存在しますが、統一のため我流で行きます。
無声破裂音「カ・タ・パ行」の場合はこういう風に「無声区間~破裂音のパルス」をラベルします。
有声破裂音「ガ・ダ・バ」の場合は「有声子音区間~破裂音のパルス」の区間にしてください。(clが長いと、画像のように有声子音区間が無声区間に変貌することがあります)
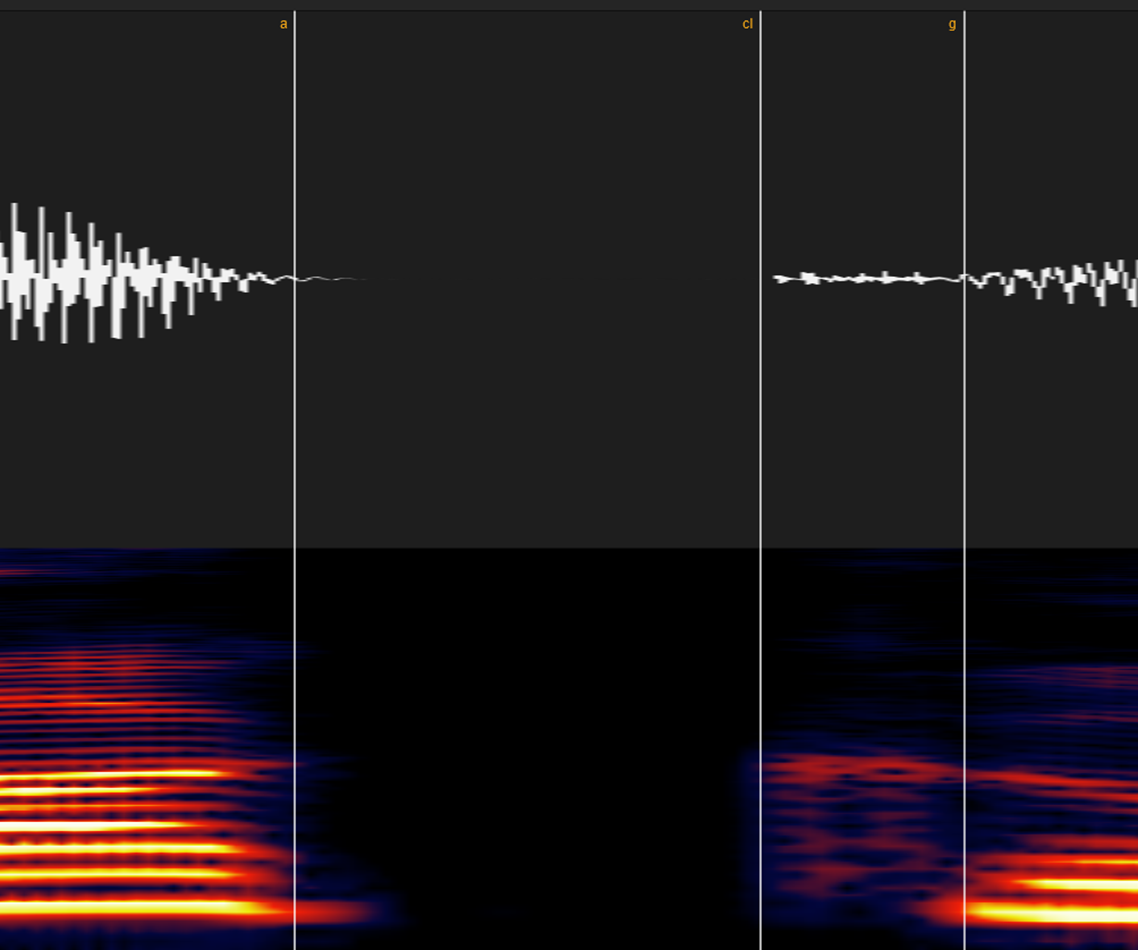
母音と母音と間の空白も同じ扱いで大丈夫です。
エッジに関しては完全に子音とみなして大丈夫です。感覚的には「エッジ音がなくなって芯が確立したとき」くらいで良いと思います。
※以下理論的な説明
メトロノームを慣らしながらエッジを入れて歌うと、基本的にはエッジがなくなって普通の声が戻ってきたときに拍が来ます。
⑫無声化(大文字のA,I,U,E,O)
続く音がサ行の場合、雰囲気を見ながら適当なところにおいてください
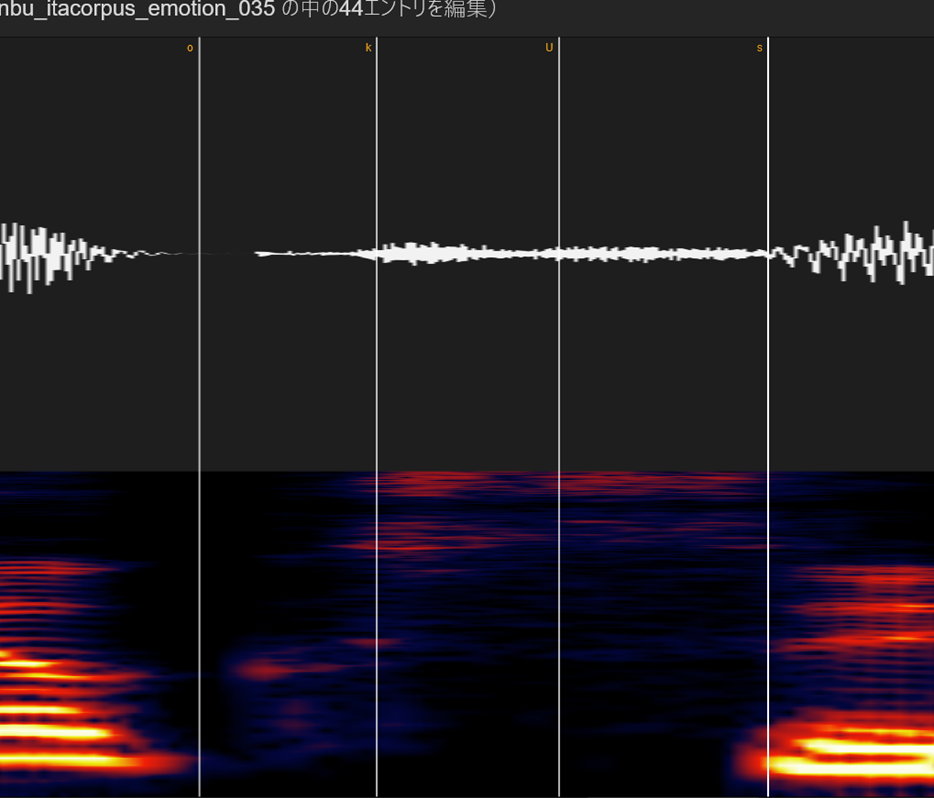
続く行が無声破裂音(カ行系)の場合は、「前の子音の後半以降をちょっとだけ+無音部分+破裂音のパルスの前」においてください
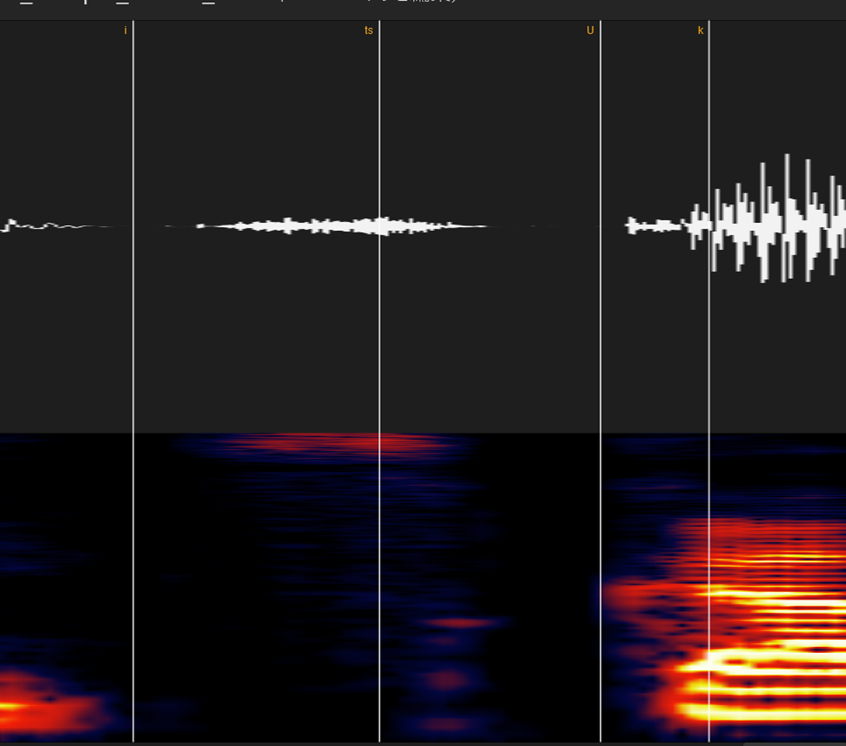
語尾の無声化の場合も大体同じです。
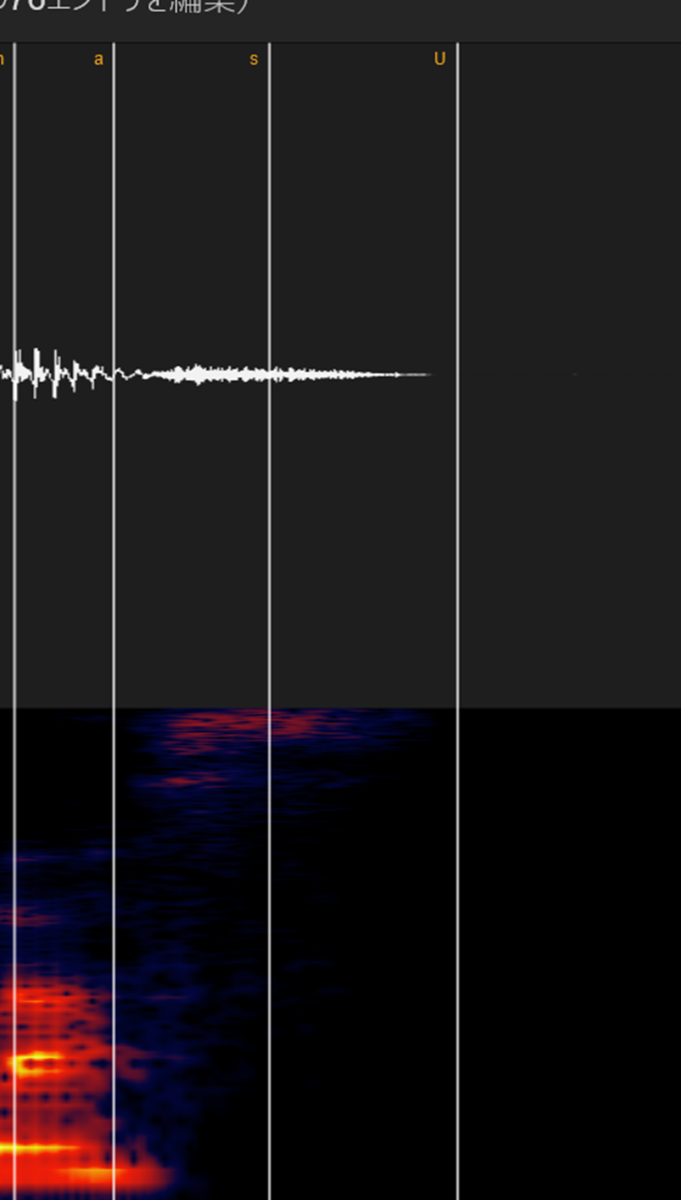
⑬出だし
出だしのタイミングで一番大事なのは「母音のタイミング」なので、出だしの子音についてはちゃんと統一さえしていれば、特に支障はないと思います。
母音についてはエッジと同じで「どこに拍が来るか」ということを考えながらラベルすれば問題ないです。
⑭NNSVS/Sinsyの仕様上の注意
語尾の後ろにSilやpauが付いているラベルについては要注意です。
私は感覚として白い線のラベルをしたくなるのですが、オレンジ色じゃないと無音区間で息を繰り返すようなノイズが鳴るらしいです。
※もしかしたら仕様変わって大丈夫になってる可能性はあるので、有識者に聞いてみてください。
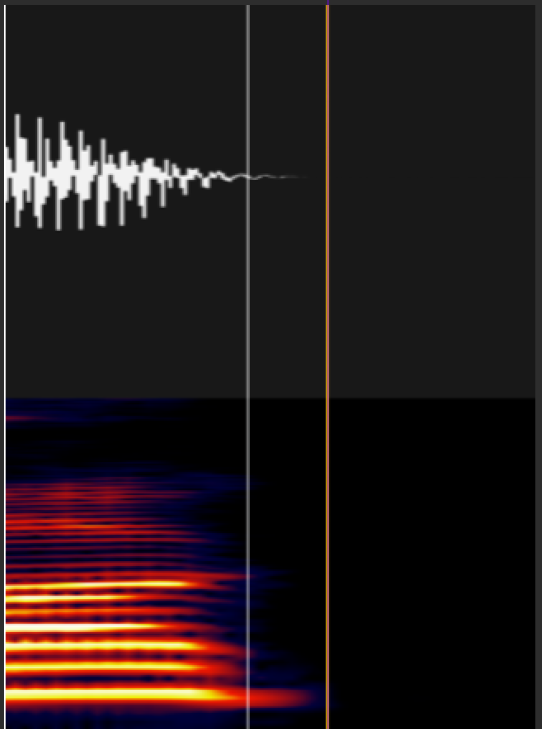
・休符系記号の区別&概念
brはフレーズの間の短い息継ぎ
pauは長い休符+フレーズに入る前の準備の息継ぎ
Silは最初と最後の無音区間
AI歌声合成?ボイチェン?Diff-SVCを徹底解説してみた!【やり方もあるよ】(2023-1-15訂正)
最近、Diff-SVCというのが海外でが流行り始めました。
AI音声合成だとも、AIボイチェンだとも、色んな言説が流布しておりますが一体「Diff-SVC」というのは何者でしょうか?
それでは早速ざっくり見てみましょう!
こんな風にDiff-SVCは「とある歌声」を「とある声質」へと高品質に変換できる技術です。
「Diff-SVC」とは?
Diff-SVCは中国のテンセントの研究部門にて開発された歌声変換AIです。
テンセントはEpic Gamesの筆頭株主で、同社が権利を持つ有名なゲームとしてはApex Legendsのモバイル版、League of Legends、PUBGのモバイル版、Pokémon UNITE、Re:ゼロから始める異世界生活 INFINITY等があります。
(恐らく「ゲームのローカライズにて声優の雰囲気を変えない」というのが開発動機かもしれません)
訂正:中国テンセントの発表論文は正確には「DiffSVC」で、Diff-SVCとDiffSVCとは全くの別物です。ちなみにこちらで紹介しているDiff-SVCは「diffsinger、diffsinger (openvpi保守版)、soft-vc」をベースに製作されたものです。
DiffSingerは中国の超名門校「浙江大学」で開発されたAI歌声合成用のニューラルボコーダーです。
Diffというのは「Diffusion」の略で、正式には「Diffusion model/拡散モデル」といいます。
これはStable Diffusion、NovelAI、Dall-E・2との画像生成AIでよく使用されています。
原理を軽く説明すると「とある画像にノイズを加えていくと、完全なノイズになる」、逆に「完全なノイズからノイズを除いていくととある画像になる」という感じです。

これを音声に適用すると「全ての音が満遍なく含まれたホワイトノイズからノイズを取り除くと、特定の音になる」という感じです

画像: Grad-TTS論文より
Diffusion Modelの合成品質はかなりは良いですが、「ノイズを取り除く演算を何度も行う」ことにより、リアルタイム性の求められる合成には向いていません。
(SynthVでは「Diffusion Probabilistic Models(DPM)モデル」としてDiffusionモデルを部分的に実装したようです。ノイズ除去演算をどうやって加速させたのかは謎です)
SVCは「Singing Voice Conversion/歌声変換」の略です。
Diff-SVCのやり方
こちらのjulieraptorの記事を参考にしました!ありがとうございます。
DIFF-SVC FOR VOCAL SYNTH USERS
①準備
音声データを最低1時間分(約300MB)、できれば3時間分(約900MB)分用意します。
これより少なくても良いですが、ある程度分量があると学習による品質向上速度が早くなります。
※1 音質さえ良ければ音程が外れてたり、噛んでたりしても問題ありません。
※2 歌声・話声・UTAU収録物、録り損じ等、何でもありです。
準備した音声データを15秒以下に切り分けます。
(いくら大きくても20秒以下が好ましいです。あまり大きすぎると学習に時間が掛かります)
AudacityのSilence Finder(無音検知)を使うと楽です
※Sound Finder(音検知)の方が変に切れることがないのでこちらを使ってください。使い方はほぼ同じです。
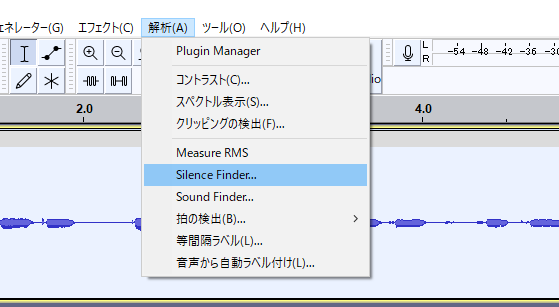
適当にパラメータを設定して適用すると、こういう感じの「S」ラベルができます。
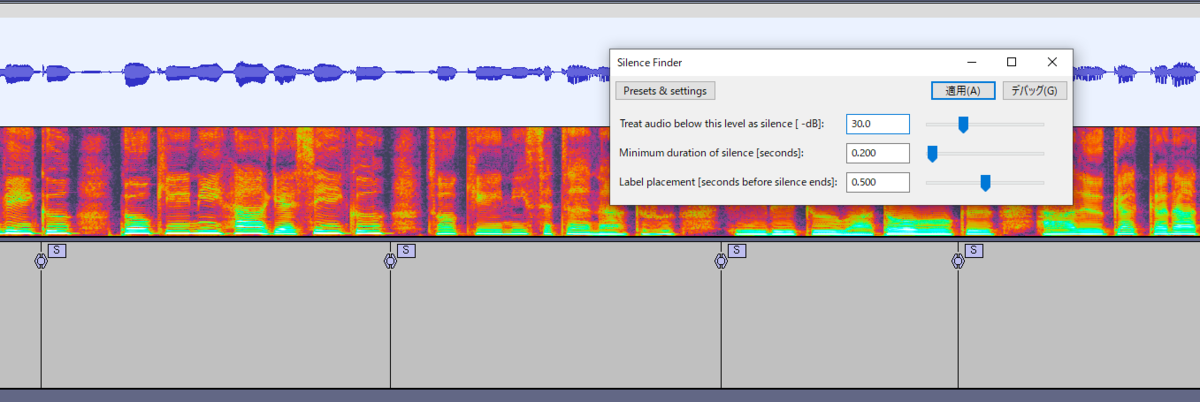
変な場所にSラベルが入っていないか調整して「複数ラベルの書き出し」から「ラベル」を選択して書き出します。
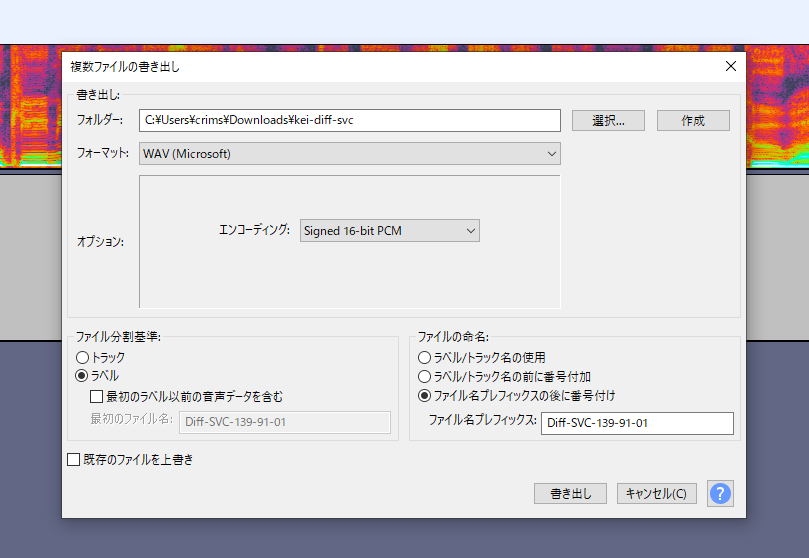
これで下準備は終了です。切り分けたwavをzipファイルにまとめて、自分のGoogle Driveにアップロードしておきましょう。
②モデルの学習
Linux環境での学習には挫折したので、Google Colabを使った学習方法について書きます。
まず、こちらのノートブックを開きます
Diff_SVC_training_notebook_(colab_ver_).ipynb | Google Colab
ここの「ドライブにコピー」をクリックして、ノートブックを自分のドライブに持って行きましょう。
ノートブックの設定からハードウェアアクセラレータが「GPU」になっている事を確認します。
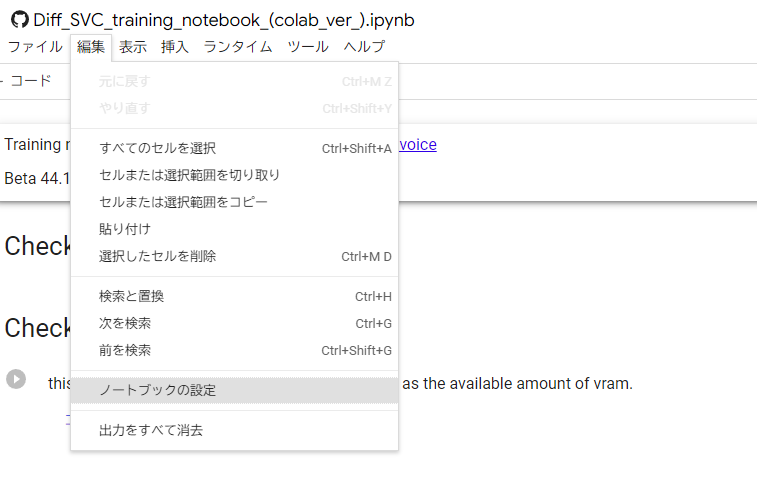

もしProに加入してる場合はプレミアムGPU+ランライムの使用をハイメモリにすると学習が速く、そして中断されにくくなります。
確認したら、ノートをひとつずつ走らせていきましょう。
Preparation
・Check GPU type
→確認のために走らせてください
・Mount Google Drive
→グーグルドライブと繋ぐための作業です、絶対にやってください。
Step 1: Install Diff-SVC(インストール)

特にこだわりが無い限り「UtaUtau's Repo」を選択してください。
サンプルレートは基本的に24kHzを選んでください。(3時間以上のデータがある人はベースモデル無しの自分の声100%による学習ができるので、44.1kHzを選んでも大丈夫です。)
アップデートで44.1kHzのベースモデルが追加されました、基本的には44.1kHzで大丈夫です。
Step 2: Decompress dataset(データの解凍)
・singer_name
→自キャラの名前なり、自分の名前なりをローマ字で入力します。(多分日本語は避けた方が無難)
・dataset_location
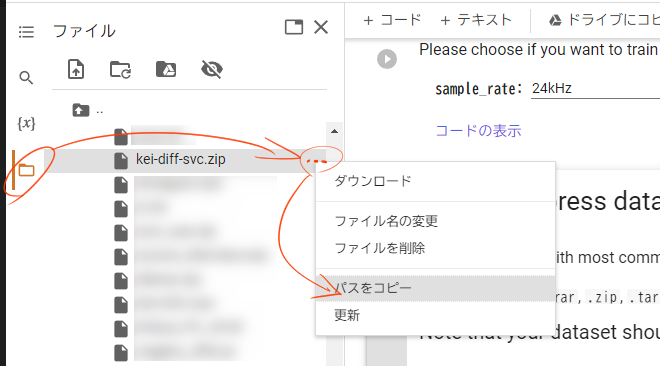
→先ほどアップロードしたwavファイルのzipのパスを入力してください。
ファイルのパスは左側ののフォルダアイコンをクリックして表示できる「ファイル」から簡単にコピーできます。(基本的には/content/drive/MyDrive/○○.zip)という感じになります。
※この動作は頻繁に使うので覚えてください
Step 2-A: Decompress training data(学習データの解凍)
今回は使いません、飛ばしてStep3に移ってください
Step 3: Edit training parameters(学習パラメータの編集)
・use_crepe
→チェックを入れる
・Set checkpoint interval
→学習何ステップ毎にモデルが生成されるかです。基本的に1000で問題ないです。Colab Proでコンピューティングユニットを買っている場合は多分5000くらいで良いです。
・Pretrain model usage
→ベースモデルありの学習に関するオプションです。
学習データが3時間以下の場合はチェックを入れると学習品質が向上します。
男声の場合はnehito、女声の場合はnyaruかopencpop、中性的な声の場合はlieeを選んでください。
※学習データが3時間以上かつ、Step 1で44.1kHzを選んだ人は使えません。
男声ならnehitoの44.1kHz、女声ならlieeの44.1kHzを選びましょう。
(lieeを使用する場合、「julieraptor」をクレジットしましょう)
・Use custom save directory
→完成したモデルをどこに置くかに関するオプションです。
Colabと接続が切れると進捗がゼロになってしまうので、基本的にはチェックを入れて「/content/drive/MyDrive/○○」など、自分のGDriveに設定しておくことをおすすめします
※ドライブの空き容量にご注意ください
・Resume training from a checkpoint
→今回は使いません
・Setup for small datasets
→音声データが少ない場合(多分30~40分以下くらい?)はチェックを入れてください
Step 4: Pre-processing
音声データを学習向けに変換します。かなり時間が掛かります。
Step 5-0 Tensorboard (run before step 5)
テンサーボード(学習の進捗状況)を表示します。上手く起動しないこともありますが大して問題はありません。
Colab Proじゃない場合はこのあたりでランタイムが切れます
Step 5: Training(学習)
学習を開始します。とりあえずランタイムが切れるまで待ちましょう。
Step 6: Package Model
Use custom save directoryオプションを使った場合は使いません。
③中断したところから再度学習
ランタイムから接続が切れた場合、途中から再度学習することができます。
事前準備
②と同じに設定してください
Step 1: Install Diff-SVC(インストール)
②と同じに設定してください
Step 2: Decompress dataset(データの解凍)
②と同じに設定してください
・dataset_location
②と同じに設定してください
Step 2-A: Decompress training data(学習データの解凍)
大幅時短できるので、ここ超大事です
・singer_name:
→Step2で設定した名前と同じ名前を入力してください
・preprocessed_data_location:
→特に問題が無ければ「/content/drive/MyDrive/diff-svc/data/○○」あたりに「シンガーの名前.7z」が入っていますので、それのパスを書きます
・config_location:
→上記と同じフォルダか、先ほど行った学習でのモデル保存場所に「config.yaml」が置いてあるのでこれを指定します。
Step 3: Edit training parameters(学習パラメータの編集)
・Resume training from a checkpoint
→前の学習で生成した最新のモデルのパスを入力してください。
それ以外は全て②と同じに設定してください。
Step 4: Pre-processing
Step 2-Aを実行したので飛ばしてください。
Step 5以降
②と同じで問題ないです。
④モデルを利用した歌声変換
さて、やっと楽しい時間がやってきました。
こちらのノートブックを開いて「ドライブにコピー」をクリックし、ノートブックを自分のドライブに持って行きましょう。
Diff_SVC_Inference.ipynb | Google Colab
Setup(セットアップ)
・Install Diff-SVC
Mode:
→初回起動の場合は「install」、もし使用中にDiff-SVC本体のアップデートが来たら「update」を選択してください
Repository:
→UtaUtaUtauを使用してください
Branch_name:
→どのバージョンのデータを利用するかです。今使ってるバージョンに致命的なバグがなければ空欄で大丈夫です。
・Mount your Gdrive
→GDirveに繋げましょう。
Load model(モデルの読み込み)
project_name:
→プロジェクトの名前です、なんでも良いです
model_path:
→先ほど生成したモデルのパスを入力してください
config_path:
→先ほど生成されたconfig.yamlファイルのパスを入力してください。
Upload your reference audio(音声のアップロード)
この機能を使って音声をアップロードすることもできますが、GDriveに直接アップロードした方が早いです
Input audio and adjust parameters
・wav_fn:
→wavファイルのパスです。GDriveに直接アップロードしたのに見つからない場合はファイルタブをパカパカするとそのうち更新されます。
・key:
→音声のキーを半音単位で変更します。しない場合でも「0」が入力されてないとエラーが出ます。大幅に変更すると滑舌等が崩壊する可能性があるので気を付けてください。
・pndm_speedup:
→値を大きくすると早く合成出来ますが、50以上にすると音質が低下するので弄らない方が良いです
・wav_gen:
→合成されたwavをどこに保存するかです。
デフォルトはランタイム内になっているので、「test_output.wav」の前に「/content/drive/MyDrive/」を付けてGDrive内に保存するよう変更するといいかもしれません。
・add_noise_step:
→use_gt_melパラメータを使用するときに使用できます。1にすると学習音声100%、、1000にすると完全にモデルの音声に寄ります。値が300付近になると、音色が混じっている感じになります。(このパラメータを非常に低く設定して、pndm_speedup値を減少させるとレンダリング品質が高くなるらしいです)
・thre:
→元音源が綺麗なら値を増やせます。音質が微妙なら値を減らしてください。
※use_crepeにチェックを入れなかった場合は使えません。
・use_crepe:
→チェックを入れるとピッチの計算方法にcrepeを使用します。
基本的にはチェックを入れると良い感じになります。オフにした場合、公式Diff-SVCレポジトリを使用した場合はparselmouth、UtaUtaUtauではHarvestが利用されます。
ただ、個人的にはUtaUtaUtauのHarvestを使った方が品質出ます。
・use_pe:
→チェックを入れるとメルケプストラムからピッチを入力し、オフにすると生音声のF0が使用されます。基本的にはチェックを入れると良い感じになります。
・use_gt_mel:
→チェックを入れると良い感じになりますが、元音声らしさは若干失われます。(説明によると、AIによる画像生成のimage-to-imageと似ていて、入力音声とターゲット音声の混合音声になるとのことです)
※キー変更機能は使えません
(雰囲気としてはこんな感じ)

・Display results&Display graph
→それぞれ「出力した音声を再生ボタン付きで表示」「変換元と変換後の音声をグラフで表示」してくれます。
前者は保存パスを指定している場合はあまりが意味が無く、後者は趣味の範疇なのでお好みでどうぞ。
⑤学習におけるアドバイス
◆データについて
・UTAU音源だけでも学習できますが、ある程度歌のデータもある方が良い感じのデータになる感触がしてます。
・どんな音声でも良いです。日本語でも英語でも韓国語でも、意味のある言葉でも、意味の無い呪文でも、もはや言語としての形態を為していなくても、歌でも、ラップでも、喋り越えでも、音痴でも、噛み噛みでも。
というのも、この学習では「声質」のみを学習するので、モデルの良し悪しは「元音声の音質」にのみ左右されます。
・「こんな音、学習して良いんだろうか……?」みたいな事を考えず、めっちゃ高い音やめっちゃ低い音を入れるとモデルの対応音域が広くなります。裏返ってても問題ないです。
・アペンド(表情)音源等を入れると恐らく表現豊かにはなりますが、データ内で声質が分散してるので良い感じの音源になるにはかなりのステップが必要だと思われます。
・多分10万stepくらい回せば大体の場合では良い感じになると思います。20万stepを超えたあたりからは趣味の世界になります。
・ノイズはある程度除いてから学習させると良い感じになります
◆Colabについて
・早く完成させたいならコンピューティングユニットを買ってプレミアムGPUで3時間くらい回すと10万ステップくらい進みます。
⑥注意点
・機械学習を不可としている音声合成ソフトが多数ありますので気を付けましょう。
A.I.VOICE, CeVIO AI, Coefont CLOUD, COEIROINK, VOICEPEAK, SHAREVOX,VOICEVOXの一部キャラ
・また、有名人や版権キャラクター等のDiff-SVCモデル製作は黒に近いグレーゾーンです。
(このあたりが参考になります)
⑦デモンストレーション
・1時間の歌・喋り等で学習した音声&ステップの比較
・4時間分のUTAU音源で学習した音声&ステップの比較
・デモソング(日本語)
・デモソング(英語)
⑧感想
技術としては物凄く面白いんですが「これって音声・歌声合成っていえるの?」という部分があってちょっともにょる部分があるような……ないような……。
スマホで手軽に自分のAIシンガーが作れる「歌叽歌叽」を試してみた!
どうもアマノケイです。
結構前に「コエステーション」という自分の声を収録するとAI歌声合成にしてくれるサービスが流行りましたね。
自分でしか使えないですが、あのサービスの登場はかなり話題になりました。
今回は歌を数曲歌うと自分のAIシンガーを作ってくれる中国のサービス「歌叽歌叽」について解説していこうと思います。
やり方
①インストールする
公式サイトからアプリとソフトをインストールしましょう。
Win, Mac, iPhone, Android版があります。
虚拟歌曲制作-虚拟歌手-作词作曲-虚拟偶像-酷狗音乐歌叽歌叽

②アプリ側の設定
歌叽歌叽で自分の歌をAI化させるにはアプリで歌声を録音する必要があります。
まずアプリを起動します。
ありがちな規約が表示されるので同意します。(公式サイトからも読めますがコピペができないのでGoogleの翻訳アプリを使って全文取得するか、ソースを開いてコピペすることをおすすめします。)

このまま進みます

未成年向けの一部機能規制についてらしいです、オンにすると多分コメント機能が規制されます。

画面下部のボタン「基地」を押すとホーム画面に飛べますが、会員登録をしてないので何も表示されていません。「去登録」を押しましょう。

こういう画面が出てきますので、同意にチェックを入れて認証方法を選びましょう。
Android:電話番号、WeChat

※ただし、電話番号は中国のものしか使えないのでAndroid勢はWeChatに登録する必要があります。
登録が完了すると「我的AI歌手」が表示され、「立即召喚」ボタンが押せるようになります。

押すとこういう画面が出てくるので進みます。

女声が男声を選ぶ画面が出てきます。
女声の場合は最低1曲、男声の場合は5曲必要です。
※歌えば歌うほど性能が向上します

ビジュアル(2種類)と名前を決め、「上传声音」をタップして歌声アップロード画面に移行します。

こんな感じで曲が出てきます。
「K歌」ボタンを押すと歌唱UIに移行することが出来ます。

こんな感じになって、伴奏のDLが終わると「開始K歌」が押せるようになります。
イヤホン側からガイドボーカルが流れてくるので、それに従って歌いましょう。

間違えた場合は、下部にある「重唱」から録り直しができます。

収録が終わると歌声を確認するUIが出てくるので「完成」を押しましょう。
もし「この曲難しい」と思ったら左上の✕→退出から曲選択UIに戻ることが出来ます。
収録終わったら曲をアップロードしましょう。

しばらく(数時間~数日)すると「我的AI歌手」から自分のAIシンガーが召喚されます、ヨシ!

③PCで自由に歌わせる方法
デスクトップ版の歌叽歌叽を起動すると右上に「未登録」というボタンが表示されます。
これをクリックするとバーコードが出てくるので、アプリ版のカメラで読み込みましょう。

下部の「宇宙」のここからカメラが起動できます。

無事認証に成功すると、歌手から自分の歌声が読み込めます。おめでとう!

④使い方
基本的にはXStudioと同じGUIです。
・歌詞の入力
中国語のみ対応しています。
・データのインポート
伴奏(wav, mid, mp3)、MIDIに対応しています。

・リバーブ
ここから調整出来ます

・パラメータの調整
右上のパラメータつまみからピッチ、タイミングを調整することが出来ます。

・音の確認/AIレンダリング
人声のスイッチをオン/オフすることでピアノ、AI合成モードに変えられます。

⑤何歌えば良いの!?
いくらAIシンガーができるとはいえ、知らない曲を歌う物はつらいものです。
なのでいくつかおすすめの曲をサジェストしておきます。
大体テンポ遅めなので歌いやすいです。
・平凡の道
バラードで歌いやすいです。割と有名な曲なので知ってるかもしれません。
・学猫叫
キズナアイちゃんが歌ってたので聞き込めば歌いやすいはず……。
・你笑起来真好看
AISingersの余袅袅の1つ目の曲なので、耳に覚えがあるかも。
・小苹果
割と有名な中国ポップス。アップテンポ曲なので気分的に覚えやすいかも。
・隱形的翅膀
中国語歌声合成のデモとしてよく使われてるので、耳に覚えがあるかも。
あとは歌詞をピンイン表示すればなんとかなると思います、これに関しては気合いです!
⑤使い勝手
中国語だと普通に良い感じに歌ってくれます!
声もめちゃくちゃ私の声です。
帰宅できたのでこれをPC版で使ってみた!
— アマノケイ (@aman0_kei) 2022年8月15日
基本的には良い感じに歌ってくれるけど、たまに音程がフラットになるのでそこは再合成が必要
手書き, Auto-tune式でピッチ描けて、タイミング調整も可能
無理矢理日本語を歌わせることも出来るから割と悪くないかも
曲:あの素晴らしい愛をもう一度 https://t.co/lE0JCPr4lM pic.twitter.com/12SShrwcuV
日本語空耳で無理矢理歌わせてみる方法はテンポが遅い曲においては有効かもしれませんが、そうでない曲だと割と微妙になりそうです。
でも日本語で無理矢理歌わせる方法を使う場合、早口気味な曲は苦手っぽい純正の(中国語音源で歌わせた場合も崩壊した)
— アマノケイ (@aman0_kei) 2022年8月15日
限りなく灰色へを歌わせた結果、「見失ってしまったのアイロニー」「バイx4」あたりが及第点になった
ust by つなまよ pic.twitter.com/dOD6rasnov
⑥補足
もしUTAUの中国語音源がある場合はそちらを使えば楽になると思います。
その場合、AndoidのPCエミュレータを使ってPC内部に流れている音声をマイクとして認識させたり、スマホのマイクに音声を直接流す必要がありますが。
あと、日本語音源しかない場合でもそれっぽい発音で歌わせると良い感じになります。
実際のところbilibili動画を見ると、日本語音源を学習させて中国語で歌わせている人がかなり居ます。
(それって大丈夫なの)(大丈夫か気になる方はこちらをご覧ください↓)
⑦感想
こういうサービスはデータ収集と引き換えにやれてるんだろうけど、日本ででもこういうのが展開されるにはきっと遠いだろうなぁ……。
むしろ海外サービスが跋扈する未来も見える。
声も顔も不気味の谷を完全突破!?(推定)世界一リアルなバーチャルアイドルが爆誕!
急にアイドルを取り上げてこのブログのコンセプトはどうなってると思っているそこのあなた、ご安心を。

今回もちゃんと歌声合成の記事です。
というわけで、早速この動画を見ていただきたいです。
何で急にK-POPのPVを見せてくるのと思った方、ご安心を。
これ、AI歌声合成です。
YuA(ハン・ユア)って誰?
ざっくり言うと、2019年にSMILEGATE社から発売されたPSVR&PCVR向けに発売された恋愛ゲーム「FOCUS on YOU」のヒロインです。
明るいけど素っ気なく、内気だけどちょっぴりドジな芸術高校2年「ハンユア」と「青春を謳歌する系」のVR恋愛ゲームのようです。
(韓国で作られたというのがあるかは不明ですが、お色気要素は皆無らしいです)
そんな「彼女」は、2021年8月にインスタを開設して精力的に活動しているようです。
実年齢も高校二年生の17歳から21歳になっていたり、リアルに年齢が変動しています。
(その過程で「人間の感情を搭載したAIであり、バーチャルヒューマンです。」などの後付け設定が付いたりしてます)
CG関連制作は韓国のメタバース系企業のジャイアントステップが担当しています。
NAVER NOW(旧ネイバーTV)のXRコンサート、SM entertainmentの次世代ガールズグループの「エスパ(AESPA)」等を展開してきた企業であり、リアルタイムエンジン技術ベースコンテンツ」ソリューションを通じて映像、広告、写真、ライブなど様々なコンテンツを高品質で制作出来る技術基盤も確保できたとのことです。
(3:19部分よりリアルタイムでのXR導入部分が見れます)
スマイルゲートは様々な自社開発IPを活用し、ゲームIPのドラマ、ハリウッド映画など様々なエンターテイメント分野の拡張を先導しており、ジャイアントステップはこのようなスマイルゲートとの協業を通じ、新しくて多様なリアルタイムエンジンベースのIPコンテンツを企画·制作する予定です。
CGで再現されたリアルな女性と聞くとSAYAを真っ先に思い浮かべますが、こちらは永遠の女子高生であるという違いがあります。
声は東芝のコエステーション(CoeAvatar)を使っていますが、音声合成の精度はかなり低いです。
松丸亮吾さんに
— Saya :CG女子 (@sayacg) 2022年4月4日
「”大人になる”ってどういうこと?」
を色々聞いてみましたhttps://t.co/0WcjaTWe2L https://t.co/k5Nizvaaaf pic.twitter.com/pJTc3GNawB
それ以外の似たコンセプトのキャラクターにはMicrosoftのりんながあります。
顔は見せておらず、声だけの存在という点で違いはあります。
歌声合成の品質も悪くはないですが、ハン・ユアと比較するとどうしても見劣って(聞劣って?)しまいます。
どうやってこの歌声AIを作ったのか?
技術提供会社なのか、自社製エンジンなのかは不明です。
ただ、スマイルゲート社のAI系情報提供サイトに「歌声合成系技術の専門家や業者の募集」があることより自社開発ではない可能性が高いです。
技術
楽譜データを入力し、音声合成技術を利用して歌う音声を作り出す技術
・必須
小規模な歌及び楽譜データベースの歌声合成
任意の声優(歌手)の3曲前後の小規模な歌及び楽譜データの確保
学習されていない楽譜データを入力したとき、当該声優の声によるボーカル音声を算出
・追加①小規模平叙文による音声ベースの歌声合成
任意の声優の小規模平叙文音声データの確保(5分前後)
学習されていない楽譜データを入力したとき、当該声優の声によるボーカルを算出②ノーリファレンスベースの歌声合成
パラメータ又はその他の方式により、本来存在しない声優(歌手)音声の構築
学習されていない楽譜データを入力した際、構成された音声をベースとしたボーカル算出
また、「スマイルゲートは神秘的な感性を持つYuA固有の声を具現するため、様々な年代の数百人のボイスデータを集めた後、人工知能(AI)で合成して最適な声を作りました。」とあるのでAIであることは確定しています。
出典:ゲームトーク(https://www.gametoc.co.kr)
制作協力が凄い!
まず、ハン・ユアはYG KPLUSと専属契約を結びました。ここはBIGBANGやBLACKPINKといったガチトップのK-POPアイドルが所属している事務所です。
韓国の事務所でもいわゆる「キワモノ枠」なのではないかといわれますが、韓国での音楽は完璧に実力至上主義です。オーディションに受かっても女性アイドルはデビューするまで約3年2ヶ月12日の間レッスンを受ける必要があるそうです。
事務所は違いますが、K-POPへのこだわりが分かるエピソードを引用しておきます。
実際、BTSの事務所の日本法人であるBig Hit Entertainment Japanの日本在住プロデューサー募集の応募要項には、「メロディーが鮮明で、ダイナミックな流れの起承転結がはっきりとした、定型化された曲の構造の音楽デモはご遠慮ください」と書いてある。これは暗にJ-POPはご遠慮くださいということだ。
出展:日経スタイル(https://style.nikkei.com/)
作詞・作曲・アレンジは「Mind Your Own Business」、MAMAMOOの「HIP」、ファサの「マリア」「TWIT」、チョンハの「SNAPPING」、「愛の不時着」「ミスターサンシャイン」「トッケビ」等のドラマOSTを手がけた「パク・ウサン」プロデューサーが担当。
振り付け担当はTWICEの「TT」「KNOCK KNOCK」「Like OOH-AHH」、MAMAMOOの「HIP」、ボアの「Fox」を手がけたワンミリオンダンススタジオ。
PV制作は「Red Velvet」「highlight」「IZ*ONE」等の映像制作を担当したVikings Leagueとのことです。
豪華すぎやろ!!!
感想
日本や中国では「初音ミク」「洛天依」といったバーチャルアイドルが人気だが、そういうアニメ的文脈を介しづらい諸外国(アメリカや韓国)は技術の発展により、ようやくマジョリティに受け入れられる「リアル系アーティスト」のプロデュースが現実的になってきたのかなって感じがします。具体的に言うとSBS主体のSeeUはコアな人気を博したが、やはり登場時期が早すぎた感じがします思っています。
そういう文脈を頭の片隅に置きながら、「League of Legends」というゲームを開発している韓国会社がプロデュースしたバーチャルアイドル「K/DA」のミュージックPVが世界的に人気になっているのを見ると不思議な感覚がします。
ちょっと違うかも知れませんが、早い段階でセガサターンを出して「早すぎる」といわれたSEGAを思い出します。(ワールドワイドにK-POPが人気を博し始めたという下地もあると思いますけど)
Exploring the mystery of the poor quality reveals Crypton's intentions【What is identity of Hatsune Miku NT?】
12/19 GMT+9
Many people seem like misunderstanding the central theme of this blog, so I should write it in advance.
1) How Hatsune Miku NT works.
2) The direction of Hatsune Miku NT and V4x is different (V4x has a higher level of perfection at this point, but NT's quality may improve in time).
3) Why did Crypton decide to create Hatsune Miku NT?
Hatsune Miku NT is, frankly, very subtle.
Except that you can draw the pitch freely, VOCALOID4 is still said to have better sound quality.

Now, let's talk about the internal functions of Hatsune Miku NT, and why Crypton created it in the first place.
Let's think about it from the output sound
Even though we are talking about the output sound, I don't think we can solve the problem by listening to the audio to look at the waveform and spectrogram with various manipulations.
①Is Hatsune Miku NT an AI Voicebank?
There are some rumors that Hatsune Miku NT is an AI sound source created with Hatsune Miku V4x and some other data, but I think this can be denied.
First of all, to confirm that it is not an AI sound source, let's try inputting some data that would break down if it were an AI sound source.
Here is the data that I inputted [s] at 120 BPM for 3 bars in CeVIO AI.
This parameter is VOL, but it's out of order, as you can see.

On the other hand, here is the data of 29 bars of [s] in Hatsune Miku NT at 120 BPM.
As you can see from the waveform below, there is no breakdown at all.

It returns decent data even when you type in phonemes with patterns that are not expected of an AI probably means that this is not an AI.
(Unless Crypton created the AI with this kind of input in mind, but I don't think they designed to type in 30 bars of silent notes.)
②Is Hatsune Miku NT a waveform synthesis software?
So, is Hatsune Miku a waveform synthesis software like VOCALOID? Is Hatsune Miku a waveform synthesizer like VOCALOID?
I think it's half yes and a half no.
First of all, most waveform synthesis software, like VOCALOID and UTAU, uses a method called "corpus-based synthesis method/Unit Selection" to synthesize songs by re-sampling "raw voice waveforms" or "voices that reproduce raw waveforms."
If you ask me if Hatsune Miku NT falls into this category, I have my doubts.
As you can see from the sound of the UTAU default engine (although it is kind of raspy), there is nothing wrong with human pronunciation.
In comparison, there are many things about Hatsune Miku NT that are "strange as human pronunciation.
It's hard to say exactly what it is, but I think the transition from consonants to vowels is particularly unnatural.
In other words, likely, Hatsune Miku NT is not "simply a waveform synthesis software that cuts and pastes a physical voice" or "a waveform synthesis software that cuts and pastes a high-quality reproduction of a physical voice."
Then what is Hatsune Miku NT?
There are many hints about "Hatsune Miku NT" identity, but only a few people seem to have noticed them.
First, let's read this sentence from the official website.

This is a 「高品位」 voice library created with newly developed resynthesis technology.
I'll talk about "resynthesis technology" later, but I'm curious about the use of "high-dignity/purity(高品位)" instead of "high quality(高品質)" here.
NT is certainly not "high quality," and the sentence would have worked without this word, so there must be a reason why "dignity" was deliberately chosen.
※Incidentally, "resynthesis" is also a synthesizer term. And this is also quite important, but please look up the meaning on your own.
Next is this word.

I'm curious about the "multi-sample point."
Usually, I would think that it means "Hatsune Miku NT is recording in multiple scales," but if that's the case, "multisample" should be fine. I wondered why they added the extra "points." I did some research and found out the surprising origin.
Sample points: raw data from an A/D converter used to calculate waveform points ("All About Oscilloscopes," published by Technotronics, April 2017).
I was surprised to learn that this is a term used in oscilloscopes and the like, but the explanation is noteworthy here.
In addition, there was an explanation of "waveform points," which I'll post here.
A digital value that represents the voltage at a certain point of a signal. The waveform points can be calculated from the sample points and stored in memory. ("All About Oscilloscopes," published by Technotronics, April 2017)
To put it simply, you can get the "sample points" from a certain sample and then calculate the "waveform points".
If we apply this to the "multi-sample point" of Hatsune Miku NT, we can say that "waveforms can be calculated from real voice samples of several pitches."
In other words, Hatsune Miku NT does not directly process waveforms but rather "extracts specific data from the voice and reconstructs it based on that data."
People, who are somewhat familiar with text-to-speech may say, "Isn't that a vocoder?" But I am convinced that it is not a vocoder.
What is the nature of resynthesis technology?
As it turns out, I think of it as a "primitive synthesizer."
It is that synthesizer that can process sine waves to produce various sounds.

I think the concept is based on the formant-singing sound source used in the PLG100-SG synthesizer developed by Yamaha to go a bit further.
※(For more details, please refer to pages 20~23 of "Vocaloid Technology(「ボーカロイド技術論」)")
Perhaps, but I think the rough structure of Hatsune Miku NT is in the form of abstractly calculating and outputting "spectral envelopes composed of integer-order harmonics (the core of voice)" and "spectral envelopes of aperiodic components (breath)" separately from the given parameters, and then merging them.
(For a detailed explanation of this term, please refer to here)
There are several reasons for this, but I'll list a few of the most promising.
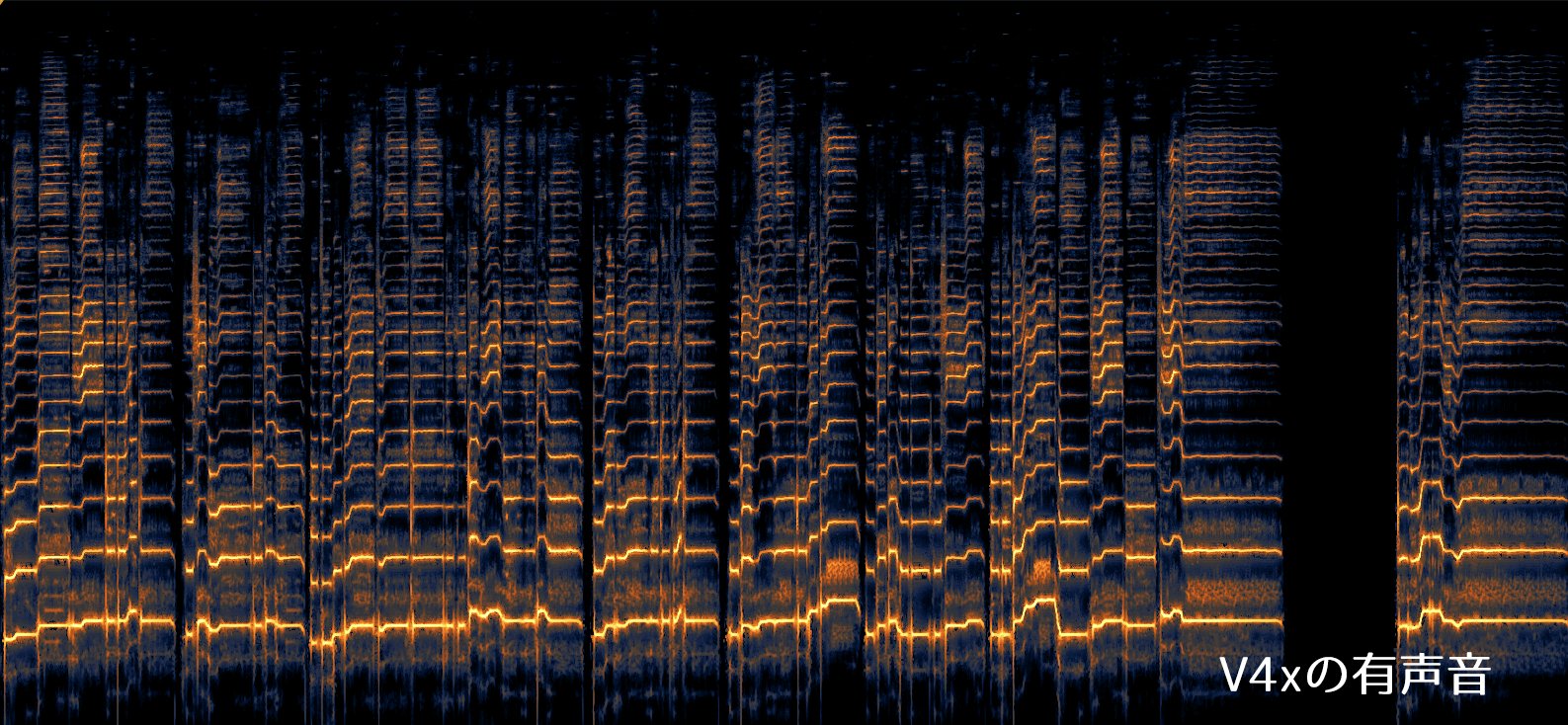
First, here is the extracted "integer harmonics (the core of voice)/voiced sound" of Hatsune Miku V4x.
In a typical real voice, the overtones of the higher parts are often mixed in with the breath components in the higher registers and cannot be extracted.
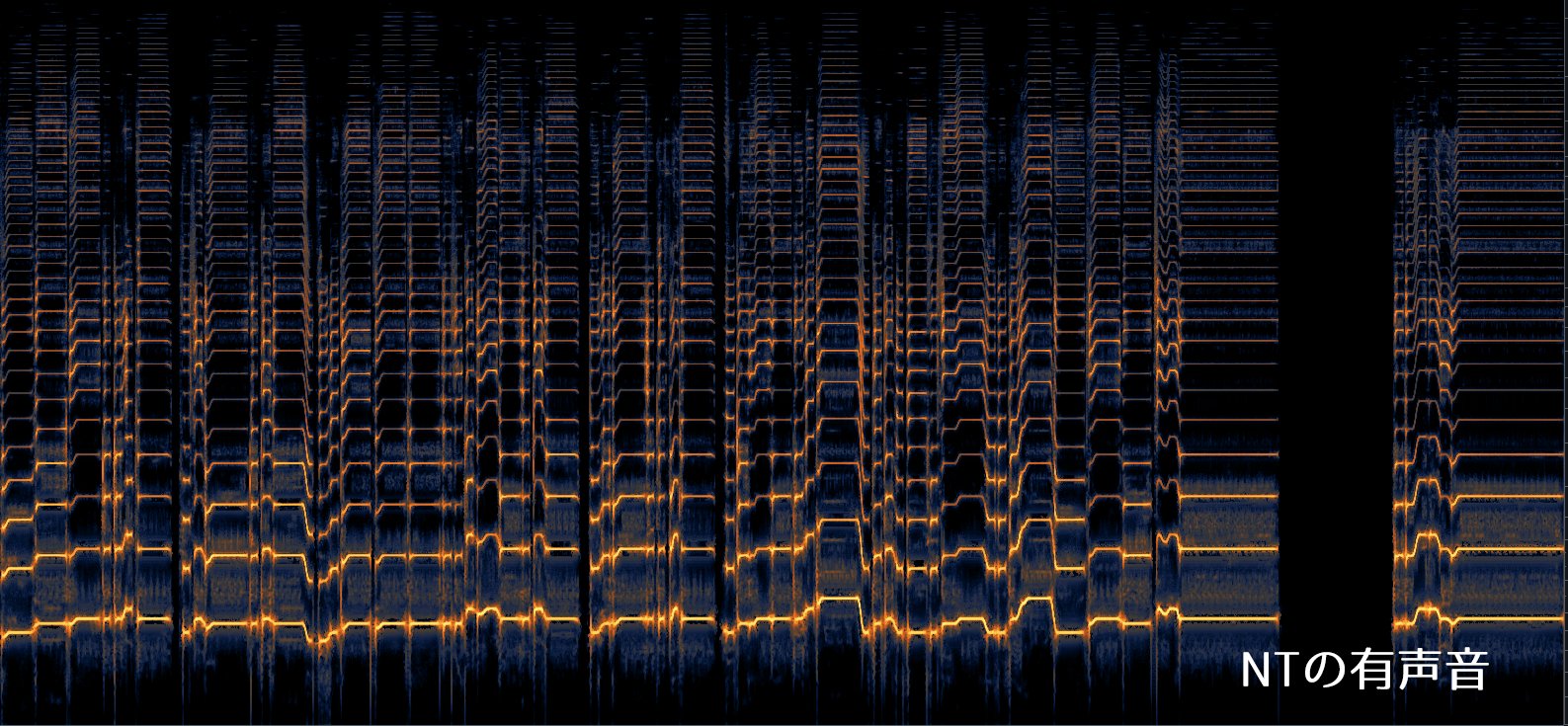
This is the extracted "integer harmonics (the core of voice)/voiced sound" of Hatsune Miku NT.
As you can see, even the overtones in the higher registers are clearly extracted to an unpleasant degree. This is a level that is impossible with the human voice.
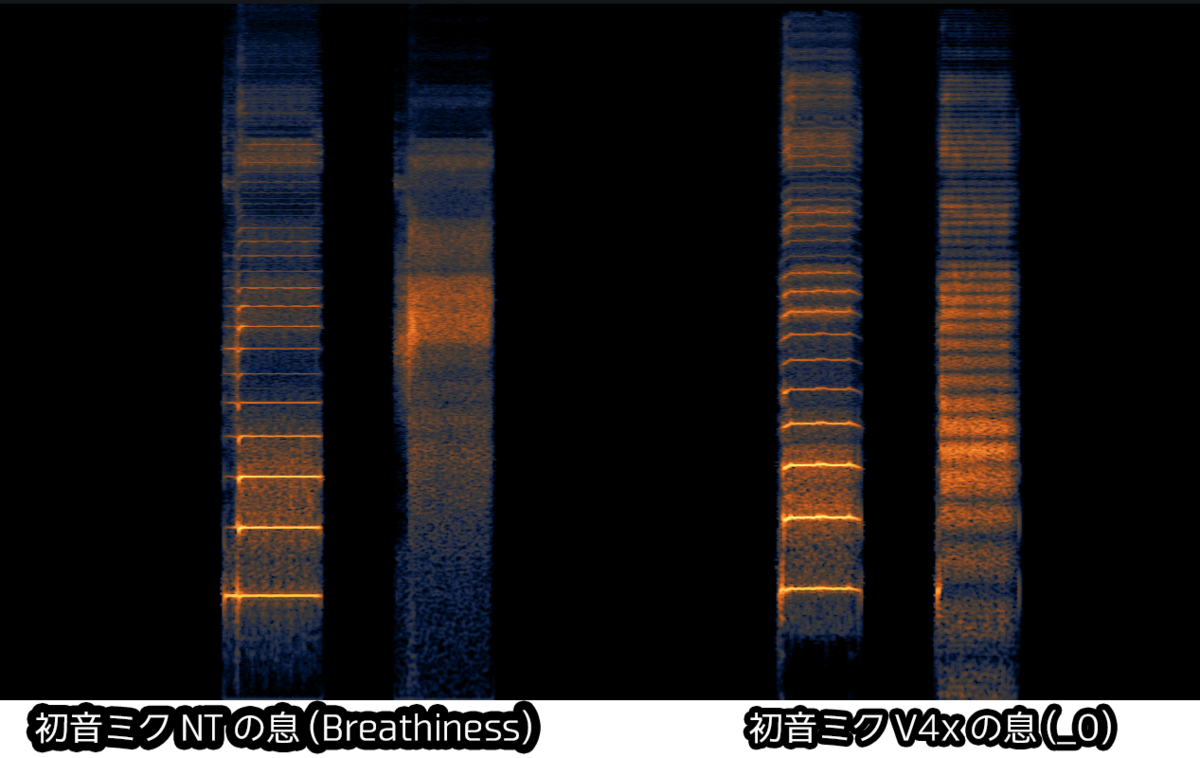
This is a sample of the "acyclic component (breath)" extracted from Hatsune Miku NT and Hatsune Miku V4x.
In Hatsune Miku V4x, the "integer harmonics (the core of voice)/voiced sound" is extracted from the original sample, and the volume is increased to make it sound like a whisper.
On the other hand, in Hatsune Miku NT, there is no correlation with the original sample at all, and it looks as if it is simulating what the "aperiodic component (breath)" in this scale would be like.
If you look at this, you can see that Hatsune Miku NT is not a "piece of a real voice" or simply a "piece of an imitated real voice" cut and pasted together.
Perhaps, if these assumptions are accurate, the internal structure of Hatsune Miku NT would look like this.
- Parameters (lyrics, pitch, and power/voltage) are input.
- Generate a pile of formants (spectral envelope) consisting of "integer harmonics (the core of voice)/voiced tones" according to the parameters.
- Based on 2, generate phoneme fragments by simulating the time direction (attack and decay timbre, etc.).
- Connect the generated fragments
- Simulate the generation of the spectral envelope of the "aperiodic component (breath)", and combine it with 4.
When you think about it, you can understand why the sounds at the border of phonemes become tricky.
I think that is why Crypton postponed the release of NT so many times. As a result, the current Hatsune Miku NT was released because the technology couldn't keep up with the direction Crypton had in mind, and "the calculus stone of soulful compromise and resignation appeared."
It is easy to reproduce vowel sounds such as long tones with a synthesizer. Still, it must be challenging to produce the instantaneous and complex sounds of vowels and consonant transition.
On the other hand, VOCALOID uses phonemes that are modeled from the original voice, and UTAU uses the original waveform, so the transition sound is cleaner.
Is Hatsune Miku NT a "New Technology"?

To put it simply, the core technology of Hatsune Miku NT is far from being "new technology."
I believe that this new technology is a "comprehensive concept that combines various existing technologies, ideas, etc.".
As proof of this, the word "new technology(新技術)" is only used here, and the other words used are "new development."
I believe that this "new technology" is based on the formant-singing function of Yamaha's PLG100-SG that I mentioned earlier. AIST might have improved the voice resolution and Crypton added various functions and UI.
I think this is what they meant when they said "we will continue to collaborate with Yamaha" at the Magical Mirai presentation. And "we can reproduce VOCALOID tones" may mean that the tone of formant-singing voicenbank will be based on VOCALOID tones.
Why did they develop Hatsune Miku NT?
In the first place, why did they develop NT instead of simply creating a voicebank with VOCALOID5?
To get a clue to this question, we have to go back to the announcement of Hatsune Miku NT at Magical Mirai.
I believe it was there that Wataru Sasaki (wat) said something like, "VOCALOID5 has a human voice mixed in, so it's not Hatsune Miku, it's Saki Fujita".
I believe this to be half true and half false.
(Please note that there will probably be a lot of speculation from here on.)
Originally, I think YAMAHA tried to add AI functions in VOCALOID5.
Unlike existing VOCALOID4 promotions, this video has a very "futuristic" feel to it. These functions and controls are all things that will be of real value when the voicebank becomes AI. (Especially the "you" in "I sing for you" around 1:04 is very unnatural)
However, if you insist on that, you will be told that VOCALOID5 will be released in 2018 and that Misora Hibari VOCALOID: AI will be announced in 2019.
However, in 2017, Pompeu Fabra University, which is developing singing voice synthesis technology in collaboration with Yamaha, published a paper called "Neural Parametric Singing Voice Synthesis," which is a precursor to the current so-called "AI singing voice synthesis technology.
The Misora Hibari AI is thought to have been created based on this.
However, since Yamaha has been updating VOCALOID every three years, the research and implementation for practical use were not ready in time for the release, and a distorted product called "VOCALOID5 without AI" was released.
With this in mind, let's look at WAT's statement again.
"VOCALOID5 has a human voice mixed in, so it's not Hatsune Miku. It's Saki Fujita."
Yes, this is not talking about VOCALOID5, but it can be taken as a statement about AI voice synthesis in general.
If you want to make Hatsune Miku into an AI, the idea would be to have Saki Fujita sing, but this is not Hatsune Miku AI. It's only "Saki Fujita AI."
That being said, even if the voice output from VOCALOID is converted into AI, it will only be a degraded version of the VOCALOID version of Hatsune Miku.
I'm going to change the subject a bit, but perhaps it's inevitable that Hatsune Miku V4x is often said to be complete than Hatsune Miku NT.
The reason for this is that V4x is "a masterpiece of VOCALOID Hatsune Miku (created by Wataru Sasaki/wat)", and Crypton has done a thorough job of specializing in VOCALOID voice processing.
(※The AHS live broadcast mentioned that "half-hearted processing will result in an error sound," so it seems that specialized processing is the only way to go.)
The official website only briefly mentions the effort, but it's probably not a level of effort or effort that ends with "carefully."
The voice database for "Hatsune Miku V4X" was carefully created by editing the voice of voice actress Saki Fujita, who recorded a large number of voices in a music studio, to include a variety of voice colors.

And it seems that Crypton did not go for AI, nor for "emulating the best of Hatsune Miku V4x", but for "a singing voice synthesis technology based on waveform synthesis that allows more flexible singing expression."
It is said that AHS was not informed of the details of VOCALOID5, so the timing may be that they saw the future of AI when NPSS was announced and made up their mind at that stage.
This is because it would take several years of research to release a new Miku when VOCALOID5 was announced.
Is it possible that Hatsune Miku will return to VOCALOID?
I think it's a possibility.
If you're wondering why Crypton didn't simply create a "Hatsune Miku AI" called "Fujita Saki AI," it's probably because they love "the existence of Hatsune Miku."
To put it simply, "Fujita Saki AI" is a misinterpretation.
At the announcement at Magical Mirai, wat-san was crying. Still, I suspect that this was because she was overwhelmed by the reality that "Hatsune Miku was born thanks to Yamaha, but for Hatsune Miku to continue to be Hatsune Miku, she will have to leave VOCALOID. I'm not really sure, though.
As I mentioned in "Is Hatsune Miku NT a New Technology?", I think AIST mainly develops the technology. Still, it wouldn't be surprising if Yamaha provided the core technology and UI-related patents technology, so I don't think it's a lie to say that Crypton and Yamaha still have a good relationship.
I think Crypton created Hatsune Miku NT because it was born in the process of getting to the final answer, "What is Hatsune Miku?"
If so, if Crypton can find an answer to the eternal question, then they might be able to make VOCALOID: AI Hatsune Miku.
Hatsune Miku has become "高品位(high-dignity/purity)"
The most common answer to the question, "When will Hatsune Miku stop being Hatsune Miku?" was when a voice actor became someone other than Saki Fujita.
And now, Hatsune Miku has gone from being "a thing made by cutting and pasting human voices" to being "a synthesizer that reproduces human voices."
You may finally understand why Hatsune Miku NT was called "高品位"
"high-dignity, high-purity"
By abstracting Hatsune Miku's voice, Hatsune Miku NT has enhanced the purity of Hatsune Miku, and I believe that this has raised her to existence and personality that is one dimension removed from reality.
From samplers to synthesizers.

Summary
Hatsune Miku NT is a new type/virtual being that could leave one dimension from the actual existence of "Saki Fujita," one of the creators of Hatsune Miku..........Maybe!
It's kind of emotional, isn't it?
※The second half of this discussion is likely to contain delusions, so I hope you will read it only for reference. I don't like it when people rag on Hatsune Miku NT, so I started thinking about why it was born, and this is what I came up with.
If this is far from the truth, I'm very sorry to Yamaha, Crypton, and WAT!
【初音ミクNTの正体】「音が悪い」理由から始まるクリプトンの意図の考察
【12/19追記】
思った以上に広まっていますが、意図が分かりやすいようにで先に主題を書いといちゃいます。
①初音ミクNTの仕組みの考察
②初音ミクNTとV4xとでは方向性が違うことの考察(V4xの方が完成度が高いが、NTは段々と品質が改善していく可能性があるということ)
③クリプトンが初音ミクNTを開発した意図の考察
※全部考察ですのでご注意ください
初音ミクNTってぶっちゃけ微妙ですよね。
ピッチを自由に描けるという自由度を除けばVOCALOID4の方がまだ音質が良いと呼ばれる始末です。
さて、今回は「初音ミクNT」が内部的にどうなっているのか、そしてクリプトンはどうして初音ミクNTを作ったのかということに付いて書いていきましょう。
出音から考えてみる
出音といっても、音声を聞いているだけでは解決できないと思うので基本的には色々な操作を加えた波形とスペクトログラムを見ていくことにします。
①初音ミクNTはAI音源なのか?
一部では「初音ミクNTは初音ミクV4xといくつかのデータを込めて作ったAI音源だ」と噂されていますが、これは明確に否定できると思います。
まず、AI音源ではではないこと確認するためにAI音源だと破綻するようなデータを入力してみましょう。
こちらはCeVIO AIの可不に[s]をBPM120で3小節分打ち込んだデータです。
このパラメータはVOLなんですが、見れば分かるとおりわかりやすく破綻しています。
一方でこちらは初音ミクNTに[s]をBPM120で29小節分打ち込んだデータです。
下の波形を見れば分かるとおり、一切破綻してません。
AIには想定されていないようなパターンの音素を打ち込んでもそれっぽいデータを返してくるということは恐らく、これはAIではないと思われます。
(万が一にこういう入力を想定してAIを作ったとかなら別ですが、流石に30小節くらいの無声音を打ち込む想定はしていないと思います)
②初音ミクNTは波形合成ソフトなのか?
そうなるとやはり初音ミクはVOCALOIDのような波形合成ソフトなのか?という考えに至ると思います。
これに関しては半分YES, 半分NOだと個人的に思ってます。
まず、大抵の波形合成ソフトはVOCALOIDやUTAUのように生の音声波形や生の波形を再現した音声をサンプリングし直すことで歌を合成する「コーパスベース合成方式/Unit Selction」という方式を採用しています。
初音ミクNTがこれに該当するかと言われると……私としては疑わしく思っています。
何故かというと、UTAUのデフォルトエンジンの音を聞けば分かるように(結構ガビガビしていますが、)人間の発音としてはおかしい要素は全くないわけです。
それに比べて、初音ミクNTは「人間の発音としておかしい」点が多数存在します。
何がどうとか具体的なことは言いづらいんですが、特に子音~母音へと遷移する音が不自然な気がします。
つまり、初音ミクNTは「単に肉声を切り貼りした波形合成ソフト」や「肉声を高品質に再現した音声を切り貼りした波形合成ソフト」という訳ではない可能性が高いです。
それなら初音ミクの正体は?
実のところ、色んなところに「初音ミクNT」の正体についてのヒントがちりばめられてはいるのですが、気付いた人はごく少数なようです。
まずは公式サイトから読み解いていきましょう。とりあえずはこの文章からです。
「リシンセシス技術」については後述するとして、ここで「高品質」ではなくて「高品位」を使っているのが気になります。
ここで言葉の定義を調べてみると「品位」=「ハイクォリティ」、「品位」=「人格的な品の良さ, 鉱物に含まれる純度の高さ」という意味です。
NTは「高品質」とは確かにいえませんし、この語がなくとも文章としては成立するはずなので、「品位」をわざわざ選んだ理由があると思われます。
次にこの語句です。
「マルチサンプルポイント」というのが気になります。
普通に考えると「初音ミクNTは多音階での収録を行っている」という意味だと思いますが、それなら「マルチサンプル」でいいはず。どうして「ポイント」が余分に付くのかが不思議です。調べてみると意外な由来が判明しました。
サンプル・ポイント:波形ポイントを計算するために使われるA/Dコンバータからの生データ(「オシロスコープのすべて」テクノトロニクス社発行 2017年4月)
オシロスコープとかで使う立派な用語だという点にもびっくりしますが、ここで注目すべきなのは解説文です。波形ポイントについても解説してあったので掲載します。
信号のある時点における電圧を表すデジタル値。波形ポイントは、サンプル・ポイントから算出でき、メモリに記憶される。(「オシロスコープのすべて」テクノトロニクス社発行 2017年4月)
意味が分からなくなってきた感がありますが簡単に言うと、とあるサンプルから「サンプルポイント」を取得し、それから「波形ポイント」を算出することが出来るということです。
これを初音ミクNTの「マルチサンプルポイント」に当てはめてみると……「いくつかの音高の生声サンプルから、波形を算出することが出来る」ということになります。
つまり初音ミクNTは波形を直接加工している訳ではなく、「生声から特定のデータを抽出し、そしてそれをベースに再構築している」というわけです。
ここである程度音声合成に詳しい人は「ボコーダーじゃないか?」ということをおっしゃるかもしれませんが、ボコーダーではないと私は確信しております。
リシンセシス技術の正体とは?
結論から言ってしまうと、「原始的なシンセサイザー」と私は考えています。
サイン波を加工して様々な音を奏でることの出来るあのシンセサイザーです。
もう少し踏み入った話をするとヤマハが開発したシンセサイザーの「PLG100-SG」に搭載されたフォルマントシンギング音源がベースの概念になっていると思います。
※詳しくは「ボーカロイド技術論の20~23ページを参照してください)
恐らくですが、初音ミクNTの大まかな構成は与えられたパラメータから抽象的に「整数次倍音(声の芯)で構成されるスペクトル包絡」「非周期成分(息)のスペクトル包絡」を個別に算出・出力した後で、それを合体させる形式だと思います。
(この用語についての詳しい説明はこちらを参照してください)
根拠はいくつかありますが、いくつか有力なもの挙げさせていただきます。
まず、こちらが初音ミクV4xの「整数次倍音(声の芯)/有声音」を抽出したものです。
一般的な生声は、高音域の息成分に混ざって高い部分の倍音が抽出できないことが多いです。
こちらが初音ミクNT「整数次倍音(声の芯)/有声音」を抽出したものです。
見れば分かると思いますが、高音域の倍音まで気持ち悪いくらいくっきり抽出できています。肉声ではあり得ないレベルです。
こちらは初音ミクNTと、初音ミクV4xから「非周期成分(息)」を終出したものです。
初音ミクV4xでは元々のサンプルから「整数次倍音(声の芯)/有声音」を抜いた上、音量を大きくすることで囁きっぽくしているような挙動がうかがえます。
一方で、初音ミクNTでは元のサンプルとの相関が全く見えず、この音階での「非周期成分(息)」はこんな感じだというシミュレーションをしているかのように見えます。
これを見ると、初音ミクNTは肉声や単に肉声を模した素片を切り貼りしたものではないということは分かると思います。
恐らく、これらの仮定が真だとすると初音ミクNTの内部構造はこうなっていると思います。
- パラメータ(歌詞、音高、パワー(ボルテージ)が入力される
- パラメータによって「整数次倍音(声の芯)/有声音」から構成されるフォルマントの山(スペクトル包絡)を生成する
- 2.をベースに、時間方向のシミュレーション(アタックや減衰の音色など)をすることで音素の素片を生成する
- 生成された素片を繋げる
- 「非周期成分(息)」のスペクトル包絡生成シミュレーションを行い、これを4.と組み合わせる
さて、そう考えると音素の境目で音が辿々しくなる理由もなんとなく分かりますよね。
シンセサイザーならロングトーン等の母音を再現するのは簡単ではありますが、母音と子音がどのように遷移するかという瞬間的かつ複雑な音を再現するのは難しいはずです。
クリプトンがNTの発売を何度も延期した結果今の初音ミクNTがリリースされたのは、技術力がクリプトンの思っていた方向性に追いつけず、「魂を込めた妥協と諦めの結石が出た」んじゃないかと思ってます。
一方でVOCALOIDは音声がモデル化されているものの、生の音声をそのまま再現した音素を使用する訳ですし、UTAUは生の波形をそのまま使うので遷移の音は綺麗になります。
初音ミクNTは「新技術」なのか?
端的に言うと、初音ミクNTの根幹技術は「新技術」とは程遠いものです。
この新技術というものは「色々な既存技術、アイデア等を組み合わせた総合的な概念」だと私は思っております。
その証拠に「新技術」という単語はここでしか使われておらず、そのほかには「新開発」という単語が使われております。
私が思うに、この「新技術」というものは先ほど言及したヤマハの「PLG100-SG」に搭載されたフォルマントシンギング機能をベースに、産総研が音声の解像度を向上させたモノだと考察しています。
マジカルミライの発表会で言及していた「ヤマハとの協業は続ける」というのはこういう意味だと思いますし、「VOCALOIDの音色も再現できる」というのはVOCALOIDの音色をベースにフォルマントシンギング音源を構成すると言う意味だった可能性があります。
どうして初音ミクNTを開発したのか?
そもそも、どうして安易にVOCALOID5で音源を作らずにNTを開発したのでしょう?
この答えに対する糸口を掴むには、マジカルミライでの初音ミクNT発表に遡ります。
そこで確か佐々木渉(wat)さんが「VOCALOID5は人間の声が混ざるので、それは初音ミクではなくて藤田咲だ」ようなことを言っていました。
これは多分VOCALOID5のアタック・リリースエフェクトで生声が混ざることを指してることを言ってますが、私はこれが半分本当で半分嘘だと思っています。
(ここからは多分に憶測が多分に入りますのでご注意ください。)
もともと、YAMAHAはVOCALOID5にてAI機能を追加しようとしたんだと思います。
この動画を見る限り既存のVOCALOID4などのプロモーションと違い、ものすごく「未来感」を感じます。そしてこれらの機能群や操作方法は、音源がAI化したときに真価を発揮するものばかりです。(特に1:04辺りの「I sing for you」の「you」がものすごく不自然)
ただ、そう主張するとVOCALOID5は2018年リリースで、美空ひばりVOCALOID:AIの発表はは2019年じゃないか、という風になると思います……が、実は2017年、ヤマハと共同で歌声合成技術の開発をしているボンペウ・ファブラ大学が、現在のいわゆる「AI歌声合成技術」の先駆けになる「ニューラルパラメトリック歌声合成」という論文を発表しています。
美空ひばりAIはこれがベースになって作られたと思われます。
ただ、ヤマハは3年ごとにVOCALOIDをアップデートしてきたこともあり、それに合わせて発表するには実用化への研究や実装が間に合わず、「AI抜きのVOCALOID5」という歪なモノがリリースされてしまったのだと思います。
これを踏まえてwatさんの発言をもう一度見てみましょう。
「VOCALOID5は人間の声が混ざるので、それは初音ミクではなくて藤田咲だ」
そう、これはVOCALOID5のことを話しているのではなく、AI歌声合成全般についての発言でもあるとも捉えられるのです。
初音ミクをAI化するなら「藤田咲に歌って貰えばいいではないか」という発想になるが、これは初音ミクAIではなくて「藤田咲AI」にしかならない、ということです。
だといって、VOCALOIDから出力された音声をAI化してもそれはVOCALOID版初音ミクの劣化版にしかならないのです。
少し話が変わりますが、初音ミクNTよりも初音ミクV4xの方が完成度が高いとよく言わるのは仕方ないのかもしれません。
何故かというと、V4xは恐らくクリプトンが徹底的にVOCALOIDに特化した音声加工を丁寧に施した「(佐々木渉の制作した)VOCALOID初音ミクの最高傑作」と呼べるからでしょう。
(※AHSの生放送では「生半可な加工だとエラー音が鳴る」と言及されていたので、特化した加工でないと駄目だと思われます。)
公式サイトではその努力がほんの少しだけ言及されていますが、多分「丁寧」で終わるレベルの努力・労力ではないでしょう。
そしてクリプトンはAIでもなく、「初音ミクV4xと言う最高傑作のエミュレート」でもなく「波形合成をベースとした、もっと柔軟な歌唱表現の出来る歌声合成技術」へと舵を切ったのだと思われます。
AHSにはVOCALOID5の詳細が伝えられなかったと言う話が出てるので、タイミングとしては恐らくNPSSが発表された時点でAI化の未来が見え、その段階で決心していたのかもしれません。
というのもVOCALOID5が発表されたあのタイミングで新型ミクを出すという話をするには数年の研究が必要な訳です。
初音ミクがVOCALOIDに復帰することはあり得るのか?
個人的には「もしかしたらあり得る」程度にに思っています。
そもそもクリプトンがどうして安易な「初音ミクAI」という名の「藤田咲AI」を作らなかったかというと、それは「初音ミクと言う存在を愛している」からでしょう。
簡単に言うと「藤田咲AI」は解釈違いということです。
マジカルミライでの発表にてwatさんは泣いていましたが、これは恐らく「初音ミクという存在が生まれたのはヤマハのおかげだが、初音ミクが初音ミクであるがために今後VOCALOIDから離れなければいけない」という現実に押しつぶされたんじゃないかと私は推測しています。
「初音ミクNTは新技術なのか?」で語ったように、技術的なのは産総研がメインで開発していると思いますが、根幹技術やUI関連の特許はヤマハが技術提供をしていてもおかしくはないわけですし、そう考えるとクリプトンとヤマハは現在でも良い関係が保てているというのは嘘ではないと思います。
私は、クリプトンが初音ミクNTを作った理由が「初音ミクとは一体何なのか?」という答えへと辿り着く過程で生まれたモノじゃないかと思っています。
もしそうであるならば、クリプトンが「初音ミクとはなんぞや?」という永遠の問いから答えを見出すことが出来たら……そのときは「VOCALOID:AI 初音ミク」ができるかもしれません。
「高品位」になった初音ミク
いつだったか「初音ミクが初音ミクじゃなくなるのはいつか?」というアンケートで一番答えが多かったのは「中の人が藤田咲じゃなくなったとき」というのがありました。
そして今、初音ミクは「人間の声を切り貼りしたモノ」から「人の声を再現するシンセサイザー」になったわけです。
ここでようやく初音ミクNTにて「高品位」という呼び方がされた理由がなんとなく分かったのではないでしょうか。
「純度の高さ、人格的な品の良さ」
初音ミクNTは、初音ミクの声を抽象化することで初音ミクの純度をより高め、それが彼女を現実から一次元離れた存在、人格へと引き上げたのではないでしょうか。
まとめ
「初音ミクNT」は、「藤田咲」という自分の生みの親の一人である現実存在である人間から一次元離れることのできたニュータイプ:バーチャル存在(本質は同じ、見た目は違うかもしれないが代わりとして使えるもの)である……かもしれない!
めっちゃエモい
※この考察(主に後半)は妄想を含んでいる可能性があるので参考程度に読んでくれると嬉しいです。初音ミクNTがボロクソ言われるのがちょっと嫌で「どうしてこれが生まれなのか」というのを考えていった結果がこうなりました。もし、真相と程遠いならヤマハさん、クリプトンさん、そしてwatさん、大変申し訳ないです!!!!!!(五体投地))
何故かCeVIO AIのマニュアルには載ってない落とし穴(+隠し機能)
CeVIO AI, いいですよね。特にIAの英語が凄く使いやすくて便利です。
ただし、日本語音源……どうしてこんなにタイミングがズレるんだ……?
というわけで、今回の解説はCeVIO AIをお使いの方ならきっと身に覚えがある「タイミングずれ」の解決方法についてのまとめです。
一部音源でタイミングがずれる
特にIA日本語, 結月ゆかり麗等の新音源で発生する現象です。(東北きりたん、さとうささらについては不明です。情報求む!)
一目見ればめちゃくちゃズレてるのが分かります

一方でこちらが可不のTMGです、非常にぴったり。

一体どうしてこのような現象が発生するのかの原因は判明していないようですが、解決方法は既に判明しております。
解決方法
調号を設定することで大体直ります。(こんなやつ)

CeVIO AIはMusicXMLというスコアベースの楽譜データを使っているので、調号の設定が比較的重要になってくる模様です。
データの冒頭に飛ぶとデフォルトの調号を変更することが出来ます。
この曲の調号はG Majorなので設定します。すると……

完璧とはいいませんが、タイミングが改善されました!

どうやって調号って判別するの?
音楽理論を学んでください(そうとしか言いようがない)
ざっくりと説明すると
音楽には「スケール」と呼ばれるものがあって、基本的にはこの範囲内の音しか使われない。(たとえば「ドレミの歌」はCメジャースケールで、使用する音は「ドレミファソラシ」の7音です。)
このCメジャースケールが基本になって、これに#や♭が加わることでスケール(調号)が変わります。

本題に入りますが、とある曲のスケールを調べたかったら「どの音が黒い鍵盤になってるか」を見れば良いです。
例えば、とある曲で黒い鍵盤が使用されているのが「ソ#」だけの場合、これはト長調(G major)かホ短調(E minor)になります。

※この場合、♯が乗っかっているラインの音符は全て#が付くことにより判別します。
「ド#とソ#の場合は……」「ラ#から始まるときは……」など色々な場合がありますが、残りは自分で判別してください。
ただ、これにも1つだけ欠点がありまして「C major」の曲の場合は調号が変えられないのでズレたまま使用するしかありません。あるいは調号は違えど中身は同じ「A minor」を設定すればなんとかなるかもしれません。
調号判別するのが苦手な人はこの表を見てください(上が♯, 下が♭です)

※一応テクノスピーチさんには報告済みなので、その内なんとかしてくれることを祈ります。
隠し機能
この前の多分AIシンガーテックにても発表した内容も若干あります。
隠し音素
SynthVで使用できる一部の特殊音素ですが、AIラベリングの方式が同じため使用できます。(音素入力してもエラーっぽい見た目になりますが普通に使用できます)
pau:軽く声を止めるときに使われる?(正しく音が生成されづらい)
Sil:強制的に音をぶった切る
cl:声門閉鎖や長子音に使える
br:強制的に息継ぎさせる
※これらを他の音素と一緒にノートへと入力すると歌詞が1文字ずつズレることがあるので気を付けてください
母音の無声化
CeVIOでは「'」を入れることで母音を脱落できることは有名……というかマニュアルに書いてありますが母音の無声化については何も書いてないです。
一見出来ないように思えますが実は出来ます。
母音のアルファベットを大文字で入力するとなんと無声化されちゃうんです
たとえば「あした」と入力する場合[a][sh, I][t, a]と入力するとちゃんと無声化してくれます。

※音素の順番や組み合わせによって上手くいく場合と行かない場合がありますが、大体どの母音でもできます。
謎の記号
これは有名ですが、ctrl+Dを押すとノートに(S)という表示が出ます(上の画像参考)
CS7だとこれ以外にB,M,Eがあるらしいんですが意味は不明です。
テクノスピーチさん教えてくれませんか~~~~!!!!
結論
カバーを作るのにも、作曲をするにも、CeVIO AIを弄るにも音楽理論は必須!